 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCProp: Adaptive Learning Rate Scaling from Past Gradient Conformity
Paper and Code
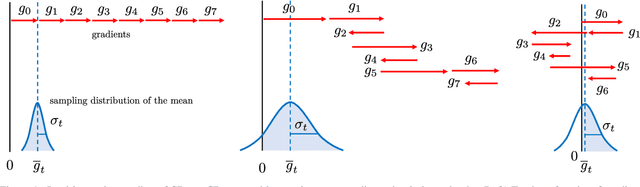
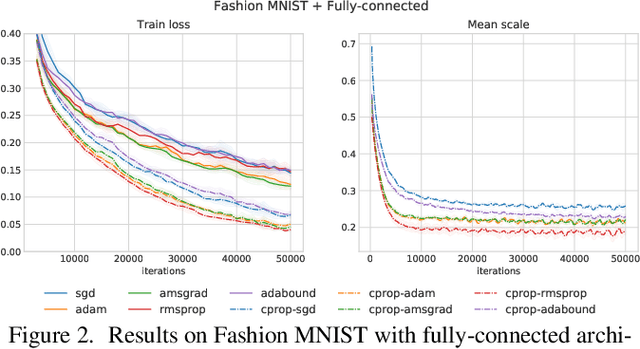

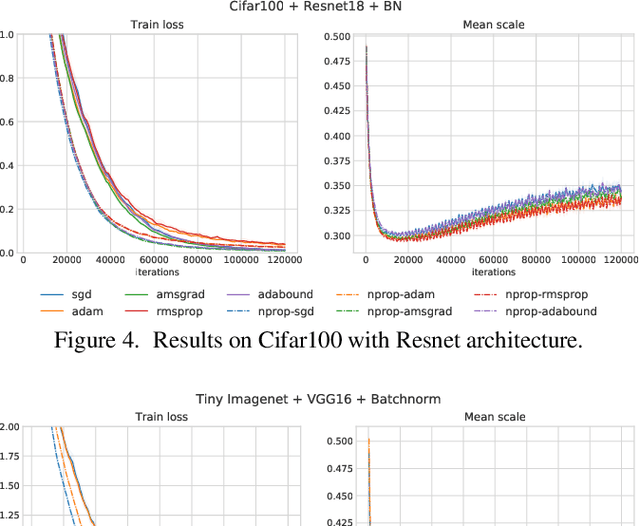
Most optimizers including stochastic gradient descent (SGD) and its adaptive gradient derivatives face the same problem where an effective learning rate during the training is vastly different. A learning rate scheduling, mostly tuned by hand, is usually employed in practice. In this paper, we propose CProp, a gradient scaling method, which acts as a second-level learning rate adapting throughout the training process based on cues from past gradient conformity. When the past gradients agree on direction, CProp keeps the original learning rate. On the contrary, if the gradients do not agree on direction, CProp scales down the gradient proportionally to its uncertainty. Since it works by scaling, it could apply to any existing optimizer extending its learning rate scheduling capability. We put CProp to a series of tests showing significant gain in training speed on both SGD and adaptive gradient method like Adam. Codes are available at https://github.com/phizaz/cprop .