 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Complex Query Answering Really Complex?
Paper and Code
Oct 16, 2024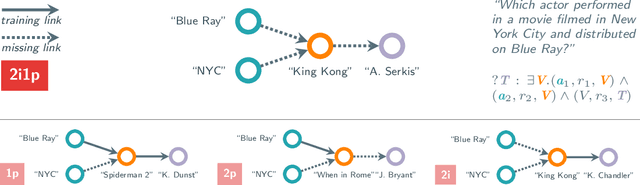
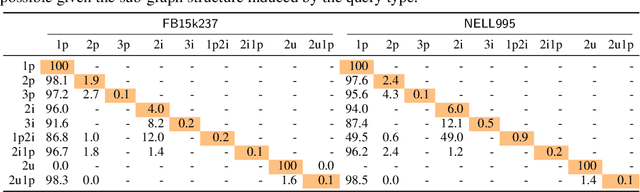

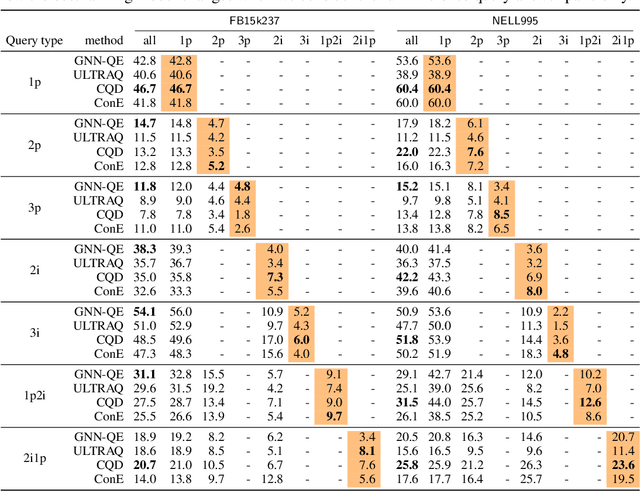
Complex query answering (CQA) on knowledge graphs (KGs) is gaining momentum as a challenging reasoning task. In this paper, we show that the current benchmarks for CQA are not really complex, and the way they are built distorts our perception of progress in this field. For example, we find that in these benchmarks, most queries (up to 98% for some query types) can be reduced to simpler problems, e.g., link prediction, where only one link needs to be predicted. The performance of state-of-the-art CQA models drops significantly when such models are evaluated on queries that cannot be reduced to easier types. Thus, we propose a set of more challenging benchmarks, composed of queries that require models to reason over multiple hops and better reflect the construction of real-world KGs. In a systematic empirical investigation, the new benchmarks show that current methods leave much to be desired from current CQA methods.