 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Debates for Transparent Bias Detection [Technical Report]
Aug 06, 2025As the use of AI systems in society grows, addressing potential biases that emerge from data or are learned by models is essential to prevent systematic disadvantages against specific groups. Several notions of (un)fairness have been proposed in the literature, alongside corresponding algorithmic methods for detecting and mitigating unfairness, but, with very few exceptions, these tend to ignore transparency. Instead, interpretability and explainability are core requirements for algorithmic fairness, even more so than for other algorithmic solutions, given the human-oriented nature of fairness. In this paper, we contribute a novel interpretable, explainable method for bias detection relying on debates about the presence of bias against individuals, based on the values of protected features for the individuals and others in their neighbourhoods. Our method builds upon techniques from formal and computational argumentation, whereby debates result from arguing about biases within and across neighbourhoods. We provide formal, quantitative, and qualitative evaluations of our method, highlighting its strengths in performance against baselines, as well as its interpretability and explainability.
Contestable AI needs Computational Argumentation
May 17, 2024
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]
Nov 26, 2023We propose ProtoArgNet, a novel interpretable deep neural architecture for image classification in the spirit of prototypical-part-learning as found, e.g. in ProtoPNet. While earlier approaches associate every class with multiple prototypical-parts, ProtoArgNet uses super-prototypes that combine prototypical-parts into single prototypical class representations. Furthermore, while earlier approaches use interpretable classification layers, e.g. logistic regression in ProtoPNet, ProtoArgNet improves accuracy with multi-layer perceptrons while relying upon an interpretable reading thereof based on a form of argumentation. ProtoArgNet is customisable to user cognitive requirements by a process of sparsification of the multi-layer perceptron/argumentation component. Also, as opposed to other prototypical-part-learning approaches, ProtoArgNet can recognise spatial relations between different prototypical-parts that are from different regions in images, similar to how CNNs capture relations between patterns recognized in earlier layers.
CAFE: Conflict-Aware Feature-wise Explanations
Oct 31, 2023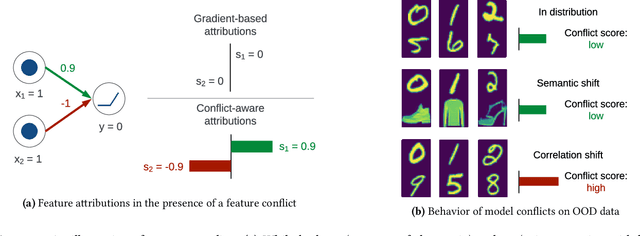
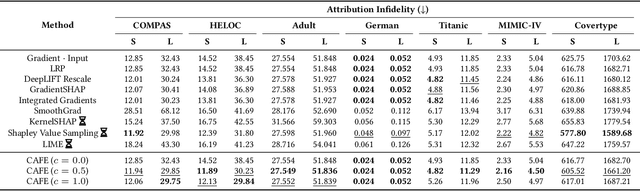
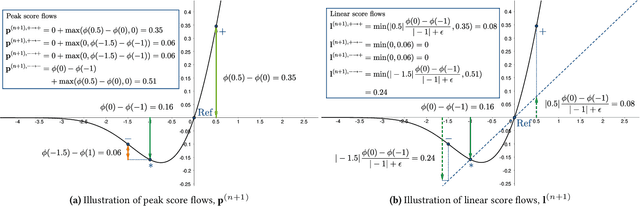
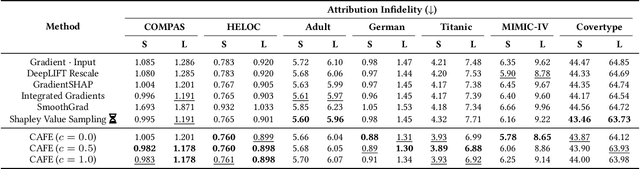
Feature attribution methods are widely used to explain neural models by determining the influence of individual input features on the models' outputs. We propose a novel feature attribution method, CAFE (Conflict-Aware Feature-wise Explanations), that addresses three limitations of the existing methods: their disregard for the impact of conflicting features, their lack of consideration for the influence of bias terms, and an overly high sensitivity to local variations in the underpinning activation functions. Unlike other methods, CAFE provides safeguards against overestimating the effects of neuron inputs and separately traces positive and negative influences of input features and biases, resulting in enhanced robustness and increased ability to surface feature conflicts. We show experimentally that CAFE is better able to identify conflicting features on synthetic tabular data and exhibits the best overall fidelity on several real-world tabular datasets, while being highly computationally efficient.
SpArX: Sparse Argumentative Explanations for Neural Networks
Jan 23, 2023Neural networks (NNs) have various applications in AI, but explaining their decision process remains challenging. Existing approaches often focus on explaining how changing individual inputs affects NNs' outputs. However, an explanation that is consistent with the input-output behaviour of an NN is not necessarily faithful to the actual mechanics thereof. In this paper, we exploit relationships between multi-layer perceptrons (MLPs) and quantitative argumentation frameworks (QAFs) to create argumentative explanations for the mechanics of MLPs. Our SpArX method first sparsifies the MLP while maintaining as much of the original mechanics as possible. It then translates the sparse MLP into an equivalent QAF to shed light on the underlying decision process of the MLP, producing global and/or local explanations. We demonstrate experimentally that SpArX can give more faithful explanations than existing approaches, while simultaneously providing deeper insights into the actual reasoning process of MLPs.