 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContestable AI needs Computational Argumentation
May 17, 2024
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
Argumentative Large Language Models for Explainable and Contestable Decision-Making
May 03, 2024The diversity of knowledge encoded in large language models (LLMs) and their ability to apply this knowledge zero-shot in a range of settings makes them a promising candidate for use in decision-making. However, they are currently limited by their inability to reliably provide outputs which are explainable and contestable. In this paper, we attempt to reconcile these strengths and weaknesses by introducing a method for supplementing LLMs with argumentative reasoning. Concretely, we introduce argumentative LLMs, a method utilising LLMs to construct argumentation frameworks, which then serve as the basis for formal reasoning in decision-making. The interpretable nature of these argumentation frameworks and formal reasoning means that any decision made by the supplemented LLM may be naturally explained to, and contested by, humans. We demonstrate the effectiveness of argumentative LLMs experimentally in the decision-making task of claim verification. We obtain results that are competitive with, and in some cases surpass, comparable state-of-the-art techniques.
Can Large Language Models perform Relation-based Argument Mining?
Feb 17, 2024
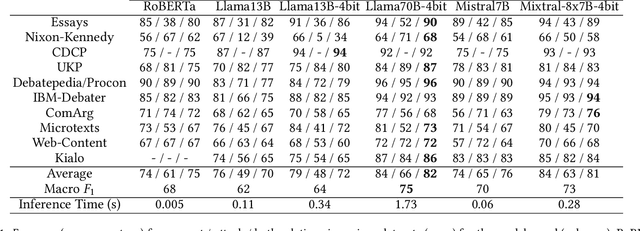


Argument mining (AM) is the process of automatically extracting arguments, their components and/or relations amongst arguments and components from text. As the number of platforms supporting online debate increases, the need for AM becomes ever more urgent, especially in support of downstream tasks. Relation-based AM (RbAM) is a form of AM focusing on identifying agreement (support) and disagreement (attack) relations amongst arguments. RbAM is a challenging classification task, with existing methods failing to perform satisfactorily. In this paper, we show that general-purpose Large Language Models (LLMs), appropriately primed and prompted, can significantly outperform the best performing (RoBERTa-based) baseline. Specifically, we experiment with two open-source LLMs (Llama-2 and Mistral) with ten datasets.