 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Debates for Transparent Bias Detection [Technical Report]
Aug 06, 2025As the use of AI systems in society grows, addressing potential biases that emerge from data or are learned by models is essential to prevent systematic disadvantages against specific groups. Several notions of (un)fairness have been proposed in the literature, alongside corresponding algorithmic methods for detecting and mitigating unfairness, but, with very few exceptions, these tend to ignore transparency. Instead, interpretability and explainability are core requirements for algorithmic fairness, even more so than for other algorithmic solutions, given the human-oriented nature of fairness. In this paper, we contribute a novel interpretable, explainable method for bias detection relying on debates about the presence of bias against individuals, based on the values of protected features for the individuals and others in their neighbourhoods. Our method builds upon techniques from formal and computational argumentation, whereby debates result from arguing about biases within and across neighbourhoods. We provide formal, quantitative, and qualitative evaluations of our method, highlighting its strengths in performance against baselines, as well as its interpretability and explainability.
PeerArg: Argumentative Peer Review with LLMs
Sep 25, 2024Peer review is an essential process to determine the quality of papers submitted to scientific conferences or journals. However, it is subjective and prone to biases. Several studies have been conducted to apply techniques from NLP to support peer review, but they are based on black-box techniques and their outputs are difficult to interpret and trust. In this paper, we propose a novel pipeline to support and understand the reviewing and decision-making processes of peer review: the PeerArg system combining LLMs with methods from knowledge representation. PeerArg takes in input a set of reviews for a paper and outputs the paper acceptance prediction. We evaluate the performance of the PeerArg pipeline on three different datasets, in comparison with a novel end-2-end LLM that uses few-shot learning to predict paper acceptance given reviews. The results indicate that the end-2-end LLM is capable of predicting paper acceptance from reviews, but a variant of the PeerArg pipeline outperforms this LLM.
Visualizing Extensions of Argumentation Frameworks as Layered Graphs
Sep 09, 2024The visualization of argumentation frameworks (AFs) is crucial for enabling a wide applicability of argumentative tools. However, their visualization is often considered only as an accompanying part of tools for computing semantics and standard graphical representations are used. We introduce a new visualization technique that draws an AF, together with an extension (as part of the input), as a 3-layer graph layout. Our technique supports the user to more easily explore the visualized AF, better understand extensions, and verify algorithms for computing semantics. To optimize the visual clarity and aesthetics of this layout, we propose to minimize edge crossings in our 3-layer drawing. We do so by an exact ILP-based approach, but also propose a fast heuristic pipeline. Via a quantitative evaluation, we show that the heuristic is feasible even for large instances, while producing at most twice as many crossings as an optimal drawing in most cases.
Argumentative Causal Discovery
May 18, 2024



Causal discovery amounts to unearthing causal relationships amongst features in data. It is a crucial companion to causal inference, necessary to build scientific knowledge without resorting to expensive or impossible randomised control trials. In this paper, we explore how reasoning with symbolic representations can support causal discovery. Specifically, we deploy assumption-based argumentation (ABA), a well-established and powerful knowledge representation formalism, in combination with causality theories, to learn graphs which reflect causal dependencies in the data. We prove that our method exhibits desirable properties, notably that, under natural conditions, it can retrieve ground-truth causal graphs. We also conduct experiments with an implementation of our method in answer set programming (ASP) on four datasets from standard benchmarks in causal discovery, showing that our method compares well against established baselines.
Contestable AI needs Computational Argumentation
May 17, 2024
AI has become pervasive in recent years, but state-of-the-art approaches predominantly neglect the need for AI systems to be contestable. Instead, contestability is advocated by AI guidelines (e.g. by the OECD) and regulation of automated decision-making (e.g. GDPR). In this position paper we explore how contestability can be achieved computationally in and for AI. We argue that contestable AI requires dynamic (human-machine and/or machine-machine) explainability and decision-making processes, whereby machines can (i) interact with humans and/or other machines to progressively explain their outputs and/or their reasoning as well as assess grounds for contestation provided by these humans and/or other machines, and (ii) revise their decision-making processes to redress any issues successfully raised during contestation. Given that much of the current AI landscape is tailored to static AIs, the need to accommodate contestability will require a radical rethinking, that, we argue, computational argumentation is ideally suited to support.
On the Correspondence of Non-flat Assumption-based Argumentation and Logic Programming with Negation as Failure in the Head
May 15, 2024The relation between (a fragment of) assumption-based argumentation (ABA) and logic programs (LPs) under stable model semantics is well-studied. However, for obtaining this relation, the ABA framework needs to be restricted to being flat, i.e., a fragment where the (defeasible) assumptions can never be entailed, only assumed to be true or false. Here, we remove this restriction and show a correspondence between non-flat ABA and LPs with negation as failure in their head. We then extend this result to so-called set-stable ABA semantics, originally defined for the fragment of non-flat ABA called bipolar ABA. We showcase how to define set-stable semantics for LPs with negation as failure in their head and show the correspondence to set-stable ABA semantics.
Instantiations and Computational Aspects of Non-Flat Assumption-based Argumentation
Apr 17, 2024



Most existing computational tools for assumption-based argumentation (ABA) focus on so-called flat frameworks, disregarding the more general case. In this paper, we study an instantiation-based approach for reasoning in possibly non-flat ABA. We make use of a semantics-preserving translation between ABA and bipolar argumentation frameworks (BAFs). By utilizing compilability theory, we establish that the constructed BAFs will in general be of exponential size. In order to keep the number of arguments and computational cost low, we present three ways of identifying redundant arguments. Moreover, we identify fragments of ABA which admit a poly-sized instantiation. We propose two algorithmic approaches for reasoning in possibly non-flat ABA. The first approach utilizes the BAF instantiation while the second works directly without constructing arguments. An empirical evaluation shows that the former outperforms the latter on many instances, reflecting the lower complexity of BAF reasoning. This result is in contrast to flat ABA, where direct approaches dominate instantiation-based approaches.
The Effect of Preferences in Abstract Argumentation Under a Claim-Centric View
Apr 28, 2022
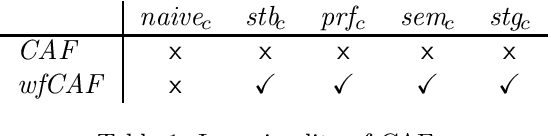
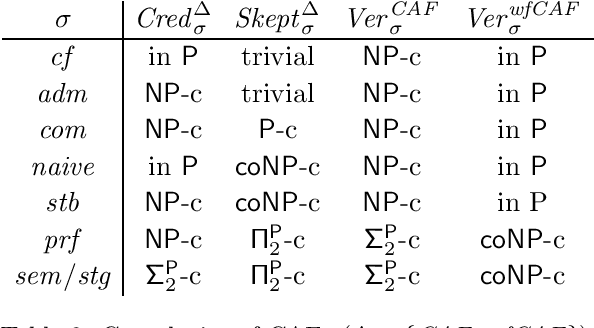

In this paper, we study the effect of preferences in abstract argumentation under a claim-centric perspective. Recent work has revealed that semantical and computational properties can change when reasoning is performed on claim-level rather than on the argument-level, while under certain natural restrictions (arguments with the same claims have the same outgoing attacks) these properties are conserved. We now investigate these effects when, in addition, preferences have to be taken into account and consider four prominent reductions to handle preferences between arguments. As we shall see, these reductions give rise to different classes of claim-augmented argumentation frameworks, and behave differently in terms of semantic properties and computational complexity. This strengthens the view that the actual choice for handling preferences has to be taken with care.