 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeerArg: Argumentative Peer Review with LLMs
Sep 25, 2024Peer review is an essential process to determine the quality of papers submitted to scientific conferences or journals. However, it is subjective and prone to biases. Several studies have been conducted to apply techniques from NLP to support peer review, but they are based on black-box techniques and their outputs are difficult to interpret and trust. In this paper, we propose a novel pipeline to support and understand the reviewing and decision-making processes of peer review: the PeerArg system combining LLMs with methods from knowledge representation. PeerArg takes in input a set of reviews for a paper and outputs the paper acceptance prediction. We evaluate the performance of the PeerArg pipeline on three different datasets, in comparison with a novel end-2-end LLM that uses few-shot learning to predict paper acceptance given reviews. The results indicate that the end-2-end LLM is capable of predicting paper acceptance from reviews, but a variant of the PeerArg pipeline outperforms this LLM.
Exploring the Effect of Explanation Content and Format on User Comprehension and Trust
Aug 30, 2024

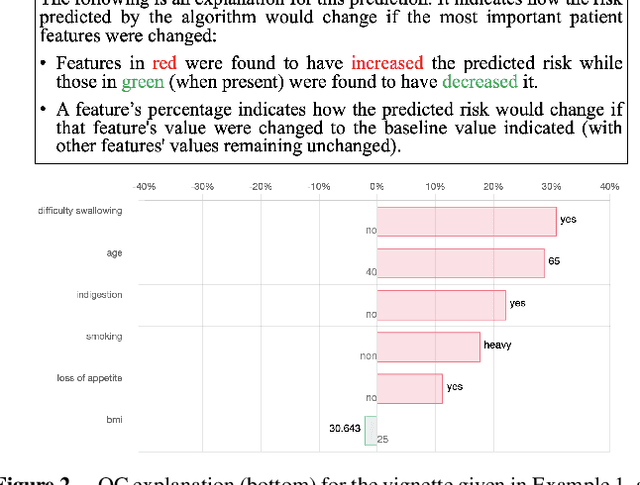

In recent years, various methods have been introduced for explaining the outputs of "black-box" AI models. However, it is not well understood whether users actually comprehend and trust these explanations. In this paper, we focus on explanations for a regression tool for assessing cancer risk and examine the effect of the explanations' content and format on the user-centric metrics of comprehension and trust. Regarding content, we experiment with two explanation methods: the popular SHAP, based on game-theoretic notions and thus potentially complex for everyday users to comprehend, and occlusion-1, based on feature occlusion which may be more comprehensible. Regarding format, we present SHAP explanations as charts (SC), as is conventional, and occlusion-1 explanations as charts (OC) as well as text (OT), to which their simpler nature also lends itself. The experiments amount to user studies questioning participants, with two different levels of expertise (the general population and those with some medical training), on their subjective and objective comprehension of and trust in explanations for the outputs of the regression tool. In both studies we found a clear preference in terms of subjective comprehension and trust for occlusion-1 over SHAP explanations in general, when comparing based on content. However, direct comparisons of explanations when controlling for format only revealed evidence for OT over SC explanations in most cases, suggesting that the dominance of occlusion-1 over SHAP explanations may be driven by a preference for text over charts as explanations. Finally, we found no evidence of a difference between the explanation types in terms of objective comprehension. Thus overall, the choice of the content and format of explanations needs careful attention, since in some contexts format, rather than content, may play the critical role in improving user experience.