 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Patient Trust in the Age of AI: Tackling Health Misinformation with Explainable AI
Sep 04, 2025AI-generated health misinformation poses unprecedented threats to patient safety and healthcare system trust globally. This white paper presents an explainable AI framework developed through the EPSRC INDICATE project to combat medical misinformation while enhancing evidence-based healthcare delivery. Our systematic review of 17 studies reveals the urgent need for transparent AI systems in healthcare. The proposed solution demonstrates 95% recall in clinical evidence retrieval and integrates novel trustworthiness classifiers achieving 76% F1 score in detecting biomedical misinformation. Results show that explainable AI can transform traditional 6-month expert review processes into real-time, automated evidence synthesis while maintaining clinical rigor. This approach offers a critical intervention to preserve healthcare integrity in the AI era.
Pub-Guard-LLM: Detecting Fraudulent Biomedical Articles with Reliable Explanations
Feb 21, 2025



A significant and growing number of published scientific articles is found to involve fraudulent practices, posing a serious threat to the credibility and safety of research in fields such as medicine. We propose Pub-Guard-LLM, the first large language model-based system tailored to fraud detection of biomedical scientific articles. We provide three application modes for deploying Pub-Guard-LLM: vanilla reasoning, retrieval-augmented generation, and multi-agent debate. Each mode allows for textual explanations of predictions. To assess the performance of our system, we introduce an open-source benchmark, PubMed Retraction, comprising over 11K real-world biomedical articles, including metadata and retraction labels. We show that, across all modes, Pub-Guard-LLM consistently surpasses the performance of various baselines and provides more reliable explanations, namely explanations which are deemed more relevant and coherent than those generated by the baselines when evaluated by multiple assessment methods. By enhancing both detection performance and explainability in scientific fraud detection, Pub-Guard-LLM contributes to safeguarding research integrity with a novel, effective, open-source tool.
Exploring the Effect of Explanation Content and Format on User Comprehension and Trust
Aug 30, 2024

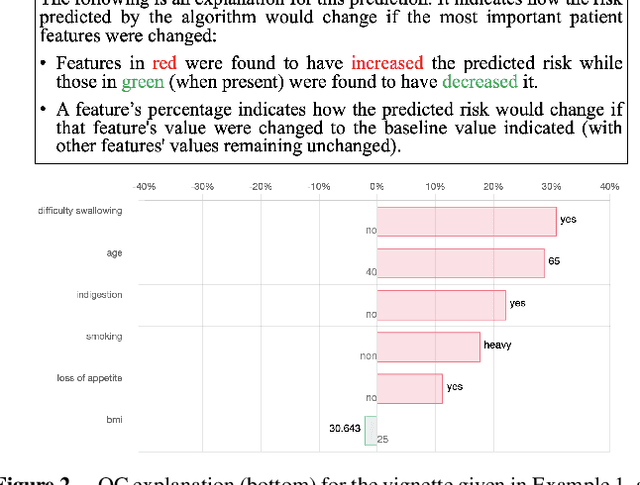

In recent years, various methods have been introduced for explaining the outputs of "black-box" AI models. However, it is not well understood whether users actually comprehend and trust these explanations. In this paper, we focus on explanations for a regression tool for assessing cancer risk and examine the effect of the explanations' content and format on the user-centric metrics of comprehension and trust. Regarding content, we experiment with two explanation methods: the popular SHAP, based on game-theoretic notions and thus potentially complex for everyday users to comprehend, and occlusion-1, based on feature occlusion which may be more comprehensible. Regarding format, we present SHAP explanations as charts (SC), as is conventional, and occlusion-1 explanations as charts (OC) as well as text (OT), to which their simpler nature also lends itself. The experiments amount to user studies questioning participants, with two different levels of expertise (the general population and those with some medical training), on their subjective and objective comprehension of and trust in explanations for the outputs of the regression tool. In both studies we found a clear preference in terms of subjective comprehension and trust for occlusion-1 over SHAP explanations in general, when comparing based on content. However, direct comparisons of explanations when controlling for format only revealed evidence for OT over SC explanations in most cases, suggesting that the dominance of occlusion-1 over SHAP explanations may be driven by a preference for text over charts as explanations. Finally, we found no evidence of a difference between the explanation types in terms of objective comprehension. Thus overall, the choice of the content and format of explanations needs careful attention, since in some contexts format, rather than content, may play the critical role in improving user experience.