 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding Patient Trust in the Age of AI: Tackling Health Misinformation with Explainable AI
Sep 04, 2025AI-generated health misinformation poses unprecedented threats to patient safety and healthcare system trust globally. This white paper presents an explainable AI framework developed through the EPSRC INDICATE project to combat medical misinformation while enhancing evidence-based healthcare delivery. Our systematic review of 17 studies reveals the urgent need for transparent AI systems in healthcare. The proposed solution demonstrates 95% recall in clinical evidence retrieval and integrates novel trustworthiness classifiers achieving 76% F1 score in detecting biomedical misinformation. Results show that explainable AI can transform traditional 6-month expert review processes into real-time, automated evidence synthesis while maintaining clinical rigor. This approach offers a critical intervention to preserve healthcare integrity in the AI era.
Pub-Guard-LLM: Detecting Fraudulent Biomedical Articles with Reliable Explanations
Feb 21, 2025



A significant and growing number of published scientific articles is found to involve fraudulent practices, posing a serious threat to the credibility and safety of research in fields such as medicine. We propose Pub-Guard-LLM, the first large language model-based system tailored to fraud detection of biomedical scientific articles. We provide three application modes for deploying Pub-Guard-LLM: vanilla reasoning, retrieval-augmented generation, and multi-agent debate. Each mode allows for textual explanations of predictions. To assess the performance of our system, we introduce an open-source benchmark, PubMed Retraction, comprising over 11K real-world biomedical articles, including metadata and retraction labels. We show that, across all modes, Pub-Guard-LLM consistently surpasses the performance of various baselines and provides more reliable explanations, namely explanations which are deemed more relevant and coherent than those generated by the baselines when evaluated by multiple assessment methods. By enhancing both detection performance and explainability in scientific fraud detection, Pub-Guard-LLM contributes to safeguarding research integrity with a novel, effective, open-source tool.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021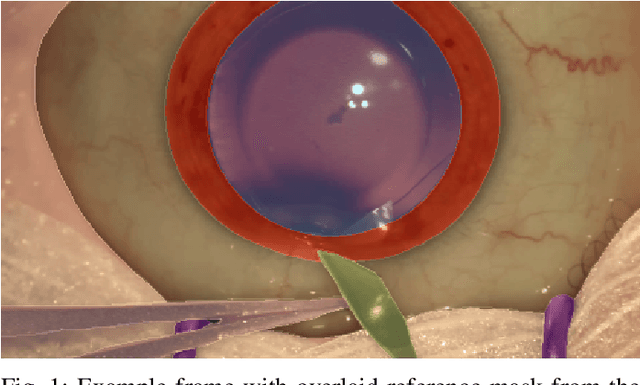
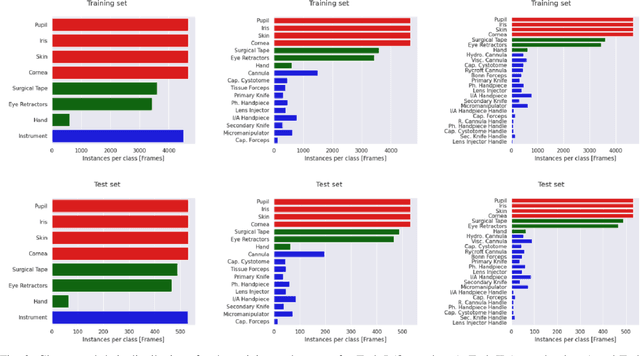
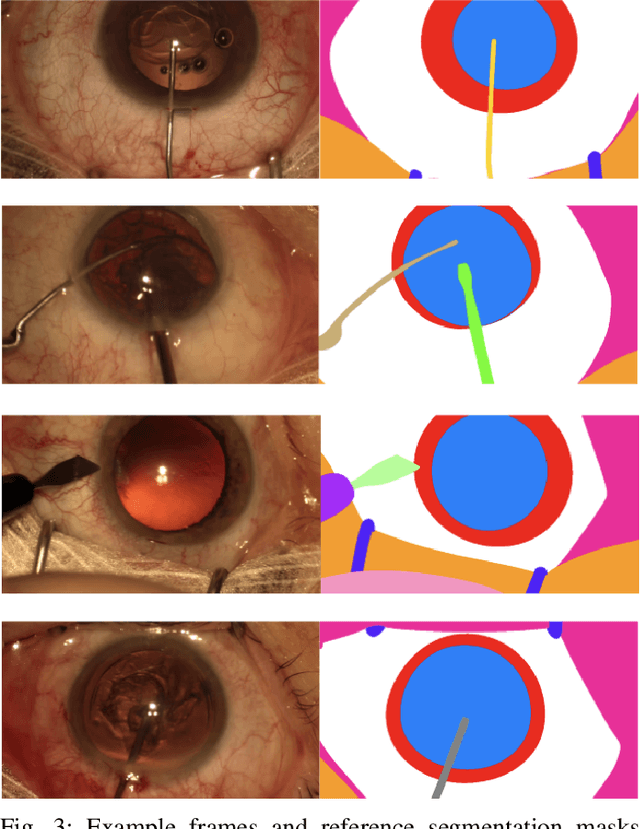
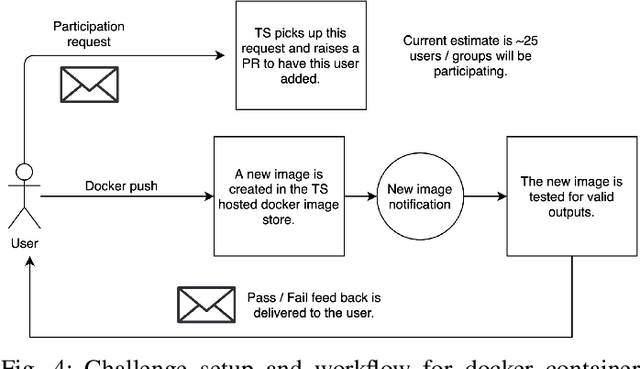
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.