 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentation for Explainable and Globally Contestable Decision Support with LLMs
Mar 15, 2026Large language models (LLMs) exhibit strong general capabilities, but their deployment in high-stakes domains is hindered by their opacity and unpredictability. Recent work has taken meaningful steps towards addressing these issues by augmenting LLMs with post-hoc reasoning based on computational argumentation, providing faithful explanations and enabling users to contest incorrect decisions. However, this paradigm is limited to pre-defined binary choices and only supports local contestation for specific instances, leaving the underlying decision logic unchanged and prone to repeated mistakes. In this paper, we introduce ArgEval, a framework that shifts from instance-specific reasoning to structured evaluation of general decision options. Rather than mining arguments solely for individual cases, ArgEval systematically maps task-specific decision spaces, builds corresponding option ontologies, and constructs general argumentation frameworks (AFs) for each option. These frameworks can then be instantiated to provide explainable recommendations for specific cases while still supporting global contestability through modification of the shared AFs. We investigate the effectiveness of ArgEval on treatment recommendation for glioblastoma, an aggressive brain tumour, and show that it can produce explainable guidance aligned with clinical practice.
Clustered Federated Learning via Embedding Distributions
Jun 09, 2025Federated learning (FL) is a widely used framework for machine learning in distributed data environments where clients hold data that cannot be easily centralised, such as for data protection reasons. FL, however, is known to be vulnerable to non-IID data. Clustered FL addresses this issue by finding more homogeneous clusters of clients. We propose a novel one-shot clustering method, EMD-CFL, using the Earth Mover's distance (EMD) between data distributions in embedding space. We theoretically motivate the use of EMDs using results from the domain adaptation literature and demonstrate empirically superior clustering performance in extensive comparisons against 16 baselines and on a range of challenging datasets.
Preference-Based Abstract Argumentation for Case-Based Reasoning (with Appendix)
Aug 03, 2024



In the pursuit of enhancing the efficacy and flexibility of interpretable, data-driven classification models, this work introduces a novel incorporation of user-defined preferences with Abstract Argumentation and Case-Based Reasoning (CBR). Specifically, we introduce Preference-Based Abstract Argumentation for Case-Based Reasoning (which we call AA-CBR-P), allowing users to define multiple approaches to compare cases with an ordering that specifies their preference over these comparison approaches. We prove that the model inherently follows these preferences when making predictions and show that previous abstract argumentation for case-based reasoning approaches are insufficient at expressing preferences over constituents of an argument. We then demonstrate how this can be applied to a real-world medical dataset sourced from a clinical trial evaluating differing assessment methods of patients with a primary brain tumour. We show empirically that our approach outperforms other interpretable machine learning models on this dataset.
CAFE: Conflict-Aware Feature-wise Explanations
Oct 31, 2023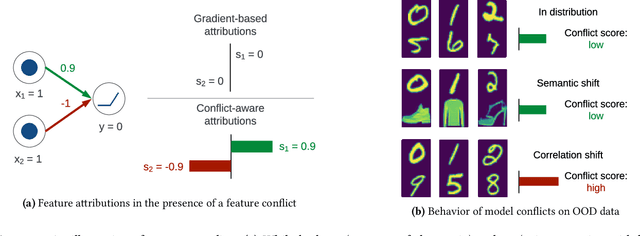
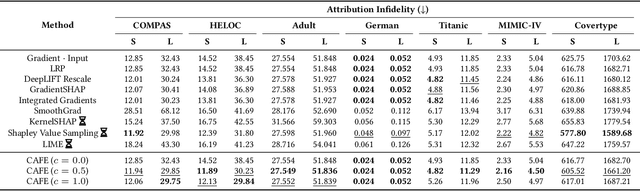
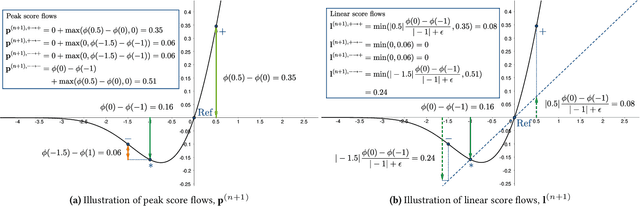
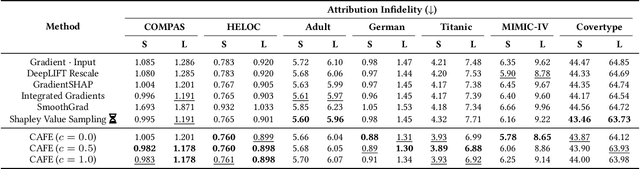
Feature attribution methods are widely used to explain neural models by determining the influence of individual input features on the models' outputs. We propose a novel feature attribution method, CAFE (Conflict-Aware Feature-wise Explanations), that addresses three limitations of the existing methods: their disregard for the impact of conflicting features, their lack of consideration for the influence of bias terms, and an overly high sensitivity to local variations in the underpinning activation functions. Unlike other methods, CAFE provides safeguards against overestimating the effects of neuron inputs and separately traces positive and negative influences of input features and biases, resulting in enhanced robustness and increased ability to surface feature conflicts. We show experimentally that CAFE is better able to identify conflicting features on synthetic tabular data and exhibits the best overall fidelity on several real-world tabular datasets, while being highly computationally efficient.
A Federated Cox Model with Non-Proportional Hazards
Jul 11, 2022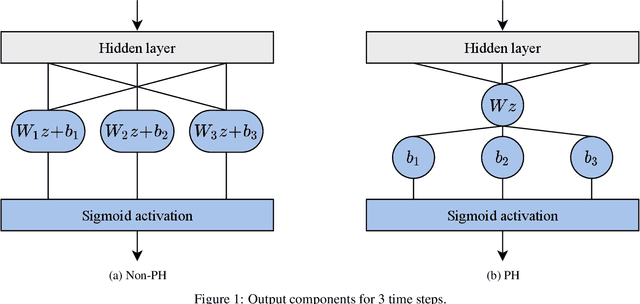

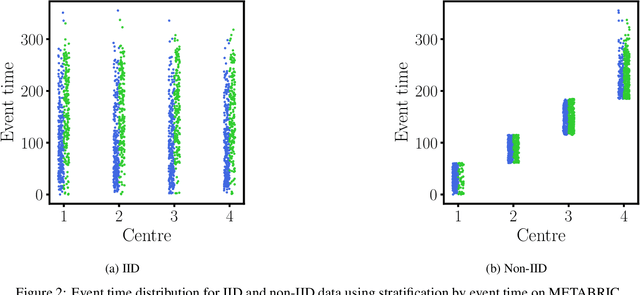

Recent research has shown the potential for neural networks to improve upon classical survival models such as the Cox model, which is widely used in clinical practice. Neural networks, however, typically rely on data that are centrally available, whereas healthcare data are frequently held in secure silos. We present a federated Cox model that accommodates this data setting and also relaxes the proportional hazards assumption, allowing time-varying covariate effects. In this latter respect, our model does not require explicit specification of the time-varying effects, reducing upfront organisational costs compared to previous works. We experiment with publicly available clinical datasets and demonstrate that the federated model is able to perform as well as a standard model.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
The Enemy Among Us: Detecting Hate Speech with Threats Based 'Othering' Language Embeddings
Mar 08, 2018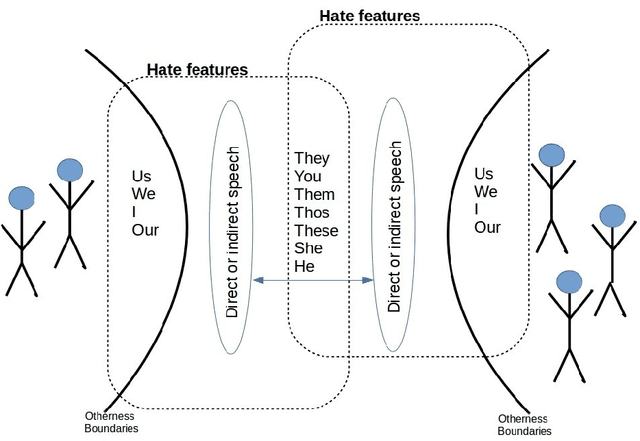
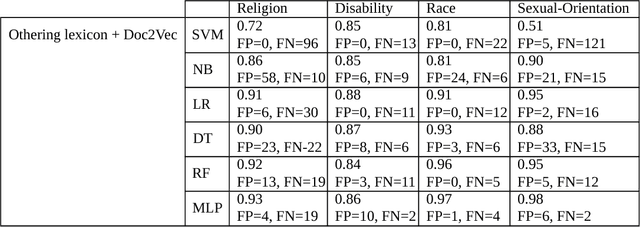
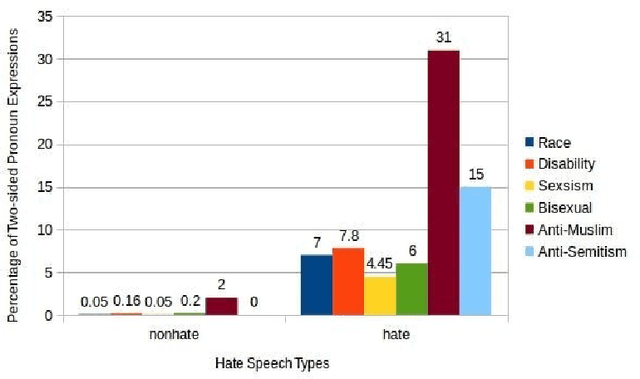
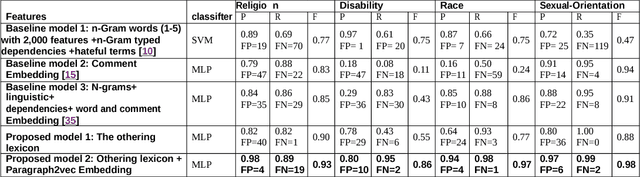
Offensive or antagonistic language targeted at individuals and social groups based on their personal characteristics (also known as cyber hate speech or cyberhate) has been frequently posted and widely circulated viathe World Wide Web. This can be considered as a key risk factor for individual and societal tension linked toregional instability. Automated Web-based cyberhate detection is important for observing and understandingcommunity and regional societal tension - especially in online social networks where posts can be rapidlyand widely viewed and disseminated. While previous work has involved using lexicons, bags-of-words orprobabilistic language parsing approaches, they often suffer from a similar issue which is that cyberhate can besubtle and indirect - thus depending on the occurrence of individual words or phrases can lead to a significantnumber of false negatives, providing inaccurate representation of the trends in cyberhate. This problemmotivated us to challenge thinking around the representation of subtle language use, such as references toperceived threats from "the other" including immigration or job prosperity in a hateful context. We propose anovel framework that utilises language use around the concept of "othering" and intergroup threat theory toidentify these subtleties and we implement a novel classification method using embedding learning to computesemantic distances between parts of speech considered to be part of an "othering" narrative. To validate ourapproach we conduct several experiments on different types of cyberhate, namely religion, disability, race andsexual orientation, with F-measure scores for classifying hateful instances obtained through applying ourmodel of 0.93, 0.86, 0.97 and 0.98 respectively, providing a significant improvement in classifier accuracy overthe state-of-the-art