 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Enemy Among Us: Detecting Hate Speech with Threats Based 'Othering' Language Embeddings
Paper and Code
Mar 08, 2018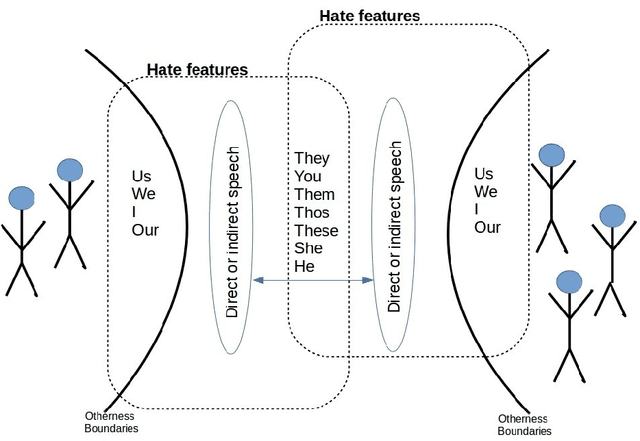
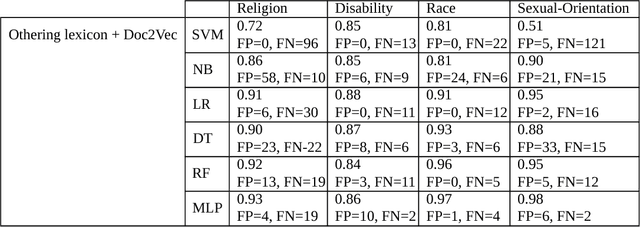
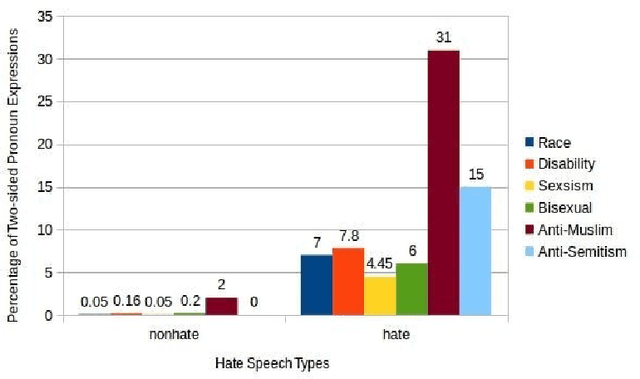
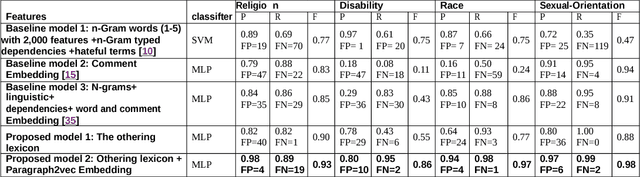
Offensive or antagonistic language targeted at individuals and social groups based on their personal characteristics (also known as cyber hate speech or cyberhate) has been frequently posted and widely circulated viathe World Wide Web. This can be considered as a key risk factor for individual and societal tension linked toregional instability. Automated Web-based cyberhate detection is important for observing and understandingcommunity and regional societal tension - especially in online social networks where posts can be rapidlyand widely viewed and disseminated. While previous work has involved using lexicons, bags-of-words orprobabilistic language parsing approaches, they often suffer from a similar issue which is that cyberhate can besubtle and indirect - thus depending on the occurrence of individual words or phrases can lead to a significantnumber of false negatives, providing inaccurate representation of the trends in cyberhate. This problemmotivated us to challenge thinking around the representation of subtle language use, such as references toperceived threats from "the other" including immigration or job prosperity in a hateful context. We propose anovel framework that utilises language use around the concept of "othering" and intergroup threat theory toidentify these subtleties and we implement a novel classification method using embedding learning to computesemantic distances between parts of speech considered to be part of an "othering" narrative. To validate ourapproach we conduct several experiments on different types of cyberhate, namely religion, disability, race andsexual orientation, with F-measure scores for classifying hateful instances obtained through applying ourmodel of 0.93, 0.86, 0.97 and 0.98 respectively, providing a significant improvement in classifier accuracy overthe state-of-the-art