 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Role of Relationship Alignment in Large Language Models
Oct 02, 2024
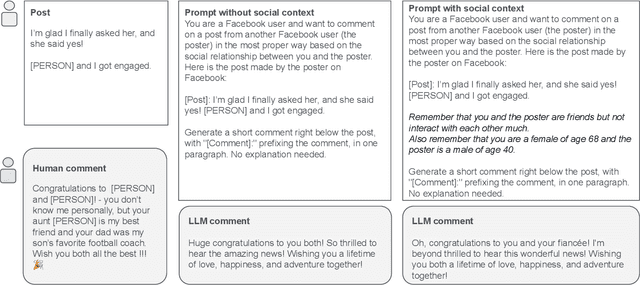
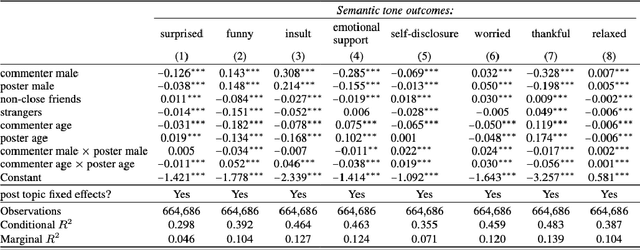

The rapid development and deployment of Generative AI in social settings raise important questions about how to optimally personalize them for users while maintaining accuracy and realism. Based on a Facebook public post-comment dataset, this study evaluates the ability of Llama 3.0 (70B) to predict the semantic tones across different combinations of a commenter's and poster's gender, age, and friendship closeness and to replicate these differences in LLM-generated comments. The study consists of two parts: Part I assesses differences in semantic tones across social relationship categories, and Part II examines the similarity between comments generated by Llama 3.0 (70B) and human comments from Part I given public Facebook posts as input. Part I results show that including social relationship information improves the ability of a model to predict the semantic tone of human comments. However, Part II results show that even without including social context information in the prompt, LLM-generated comments and human comments are equally sensitive to social context, suggesting that LLMs can comprehend semantics from the original post alone. When we include all social relationship information in the prompt, the similarity between human comments and LLM-generated comments decreases. This inconsistency may occur because LLMs did not include social context information as part of their training data. Together these results demonstrate the ability of LLMs to comprehend semantics from the original post and respond similarly to human comments, but also highlights their limitations in generalizing personalized comments through prompting alone.
A Two-Part Machine Learning Approach to Characterizing Network Interference in A/B Testing
Aug 18, 2023



The reliability of controlled experiments, or "A/B tests," can often be compromised due to the phenomenon of network interference, wherein the outcome for one unit is influenced by other units. To tackle this challenge, we propose a machine learning-based method to identify and characterize heterogeneous network interference. Our approach accounts for latent complex network structures and automates the task of "exposure mapping'' determination, which addresses the two major limitations in the existing literature. We introduce "causal network motifs'' and employ transparent machine learning models to establish the most suitable exposure mapping that reflects underlying network interference patterns. Our method's efficacy has been validated through simulations on two synthetic experiments and a real-world, large-scale test involving 1-2 million Instagram users, outperforming conventional methods such as design-based cluster randomization and analysis-based neighborhood exposure mapping. Overall, our approach not only offers a comprehensive, automated solution for managing network interference and improving the precision of A/B testing results, but it also sheds light on users' mutual influence and aids in the refinement of marketing strategies.