 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Characterization Toolkit
Paper and Code
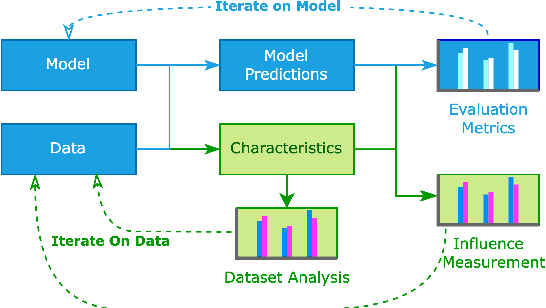
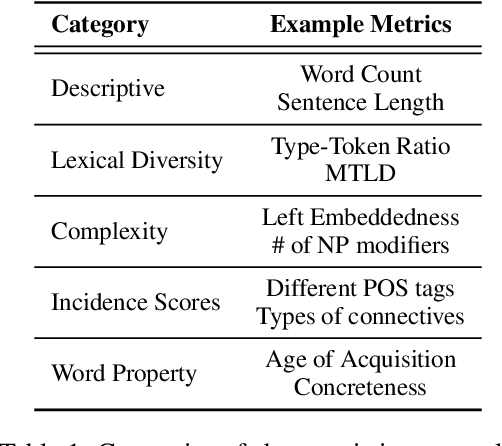
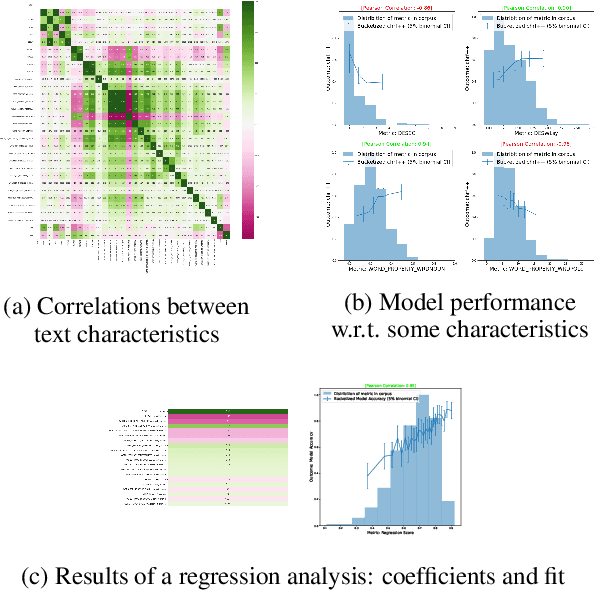
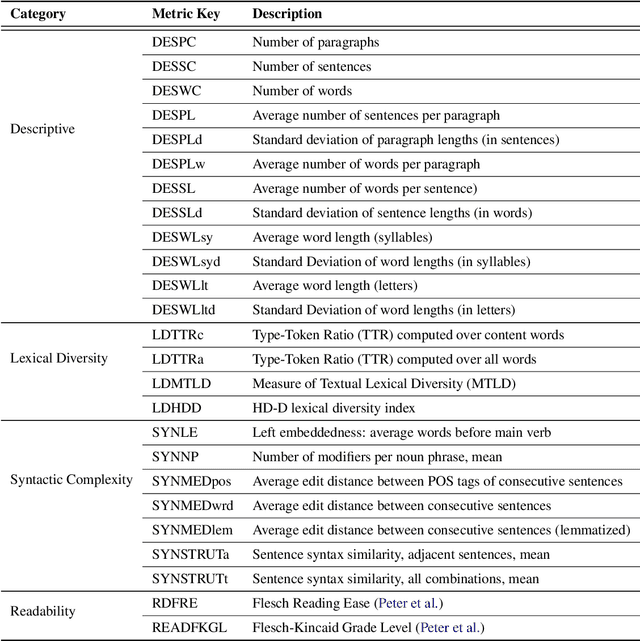
In NLP, models are usually evaluated by reporting single-number performance scores on a number of readily available benchmarks, without much deeper analysis. Here, we argue that - especially given the well-known fact that benchmarks often contain biases, artefacts, and spurious correlations - deeper results analysis should become the de-facto standard when presenting new models or benchmarks. We present a tool that researchers can use to study properties of the dataset and the influence of those properties on their models' behaviour. Our Text Characterization Toolkit includes both an easy-to-use annotation tool, as well as off-the-shelf scripts that can be used for specific analyses. We also present use-cases from three different domains: we use the tool to predict what are difficult examples for given well-known trained models and identify (potentially harmful) biases and heuristics that are present in a dataset.