 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
Paper and Code
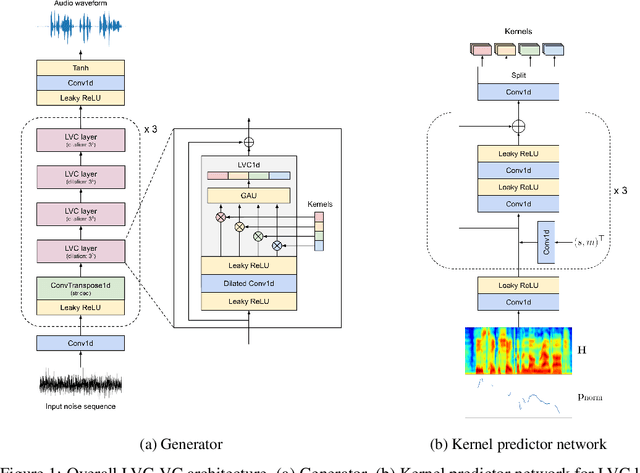
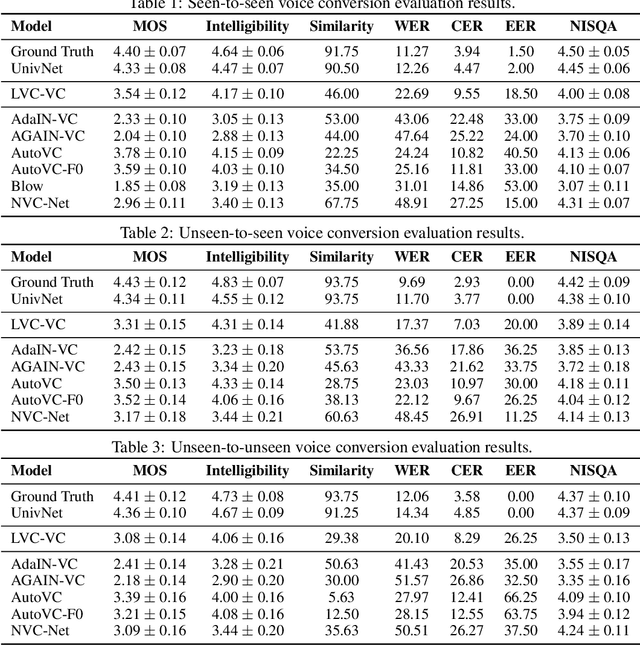

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.