 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE(3)-Equivariant Robot Learning and Control: A Tutorial Survey
Mar 12, 2025



Recent advances in deep learning and Transformers have driven major breakthroughs in robotics by employing techniques such as imitation learning, reinforcement learning, and LLM-based multimodal perception and decision-making. However, conventional deep learning and Transformer models often struggle to process data with inherent symmetries and invariances, typically relying on large datasets or extensive data augmentation. Equivariant neural networks overcome these limitations by explicitly integrating symmetry and invariance into their architectures, leading to improved efficiency and generalization. This tutorial survey reviews a wide range of equivariant deep learning and control methods for robotics, from classic to state-of-the-art, with a focus on SE(3)-equivariant models that leverage the natural 3D rotational and translational symmetries in visual robotic manipulation and control design. Using unified mathematical notation, we begin by reviewing key concepts from group theory, along with matrix Lie groups and Lie algebras. We then introduce foundational group-equivariant neural network design and show how the group-equivariance can be obtained through their structure. Next, we discuss the applications of SE(3)-equivariant neural networks in robotics in terms of imitation learning and reinforcement learning. The SE(3)-equivariant control design is also reviewed from the perspective of geometric control. Finally, we highlight the challenges and future directions of equivariant methods in developing more robust, sample-efficient, and multi-modal real-world robotic systems.
Denoising Heat-inspired Diffusion with Insulators for Collision Free Motion Planning
Oct 19, 2023



Diffusion models have risen as a powerful tool in robotics due to their flexibility and multi-modality. While some of these methods effectively address complex problems, they often depend heavily on inference-time obstacle detection and require additional equipment. Addressing these challenges, we present a method that, during inference time, simultaneously generates only reachable goals and plans motions that avoid obstacles, all from a single visual input. Central to our approach is the novel use of a collision-avoiding diffusion kernel for training. Through evaluations against behavior-cloning and classical diffusion models, our framework has proven its robustness. It is particularly effective in multi-modal environments, navigating toward goals and avoiding unreachable ones blocked by obstacles, while ensuring collision avoidance.
Diffusion-EDFs: Bi-equivariant Denoising Generative Modeling on SE(3) for Visual Robotic Manipulation
Sep 07, 2023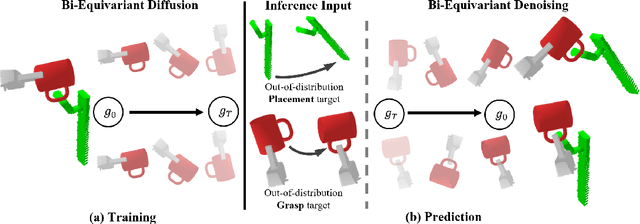



Recent studies have verified that equivariant methods can significantly improve the data efficiency, generalizability, and robustness in robot learning. Meanwhile, denoising diffusion-based generative modeling has recently gained significant attention as a promising approach for robotic manipulation learning from demonstrations with stochastic behaviors. In this paper, we present Diffusion-EDFs, a novel approach that incorporates spatial roto-translation equivariance, i.e., SE(3)-equivariance to diffusion generative modeling. By integrating SE(3)-equivariance into our model architectures, we demonstrate that our proposed method exhibits remarkable data efficiency, requiring only 5 to 10 task demonstrations for effective end-to-end training. Furthermore, our approach showcases superior generalizability compared to previous diffusion-based manipulation methods.
Equivariant Descriptor Fields: SE(3)-Equivariant Energy-Based Models for End-to-End Visual Robotic Manipulation Learning
Jun 16, 2022
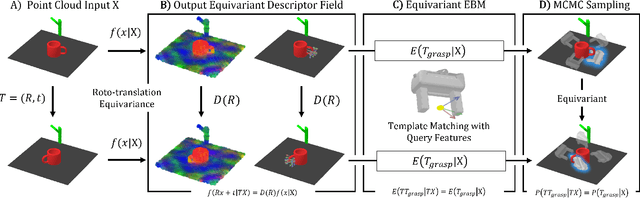

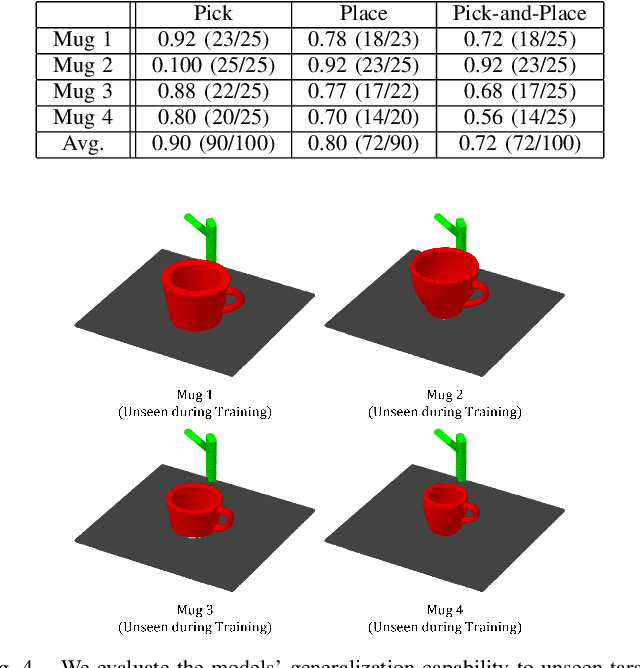
End-to-end learning for visual robotic manipulation is known to suffer from sample inefficiency, requiring a large number of demonstrations. The spatial roto-translation equivariance, or the SE(3)-equivariance can be exploited to improve the sample efficiency for learning robotic manipulation. In this paper, we present fully end-to-end SE(3)-equivariant models for visual robotic manipulation from a point cloud input. By utilizing the representation theory of the Lie group, we construct novel SE(3)-equivariant energy-based models that allow highly sample efficient end-to-end learning. We show that our models can learn from scratch without prior knowledge yet is highly sample efficient (~10 demonstrations are enough). Furthermore, we show that the trained models can generalize to tasks with (i) previously unseen target object poses, (ii) previously unseen target object instances of the category, and (iii) previously unseen visual distractors. We experiment with 6-DoF robotic manipulation tasks to validate our models' sample efficiency and generalizability. Codes are available at: https://github.com/tomato1mule/edf