 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Descriptor Fields: SE(3)-Equivariant Energy-Based Models for End-to-End Visual Robotic Manipulation Learning
Jun 16, 2022
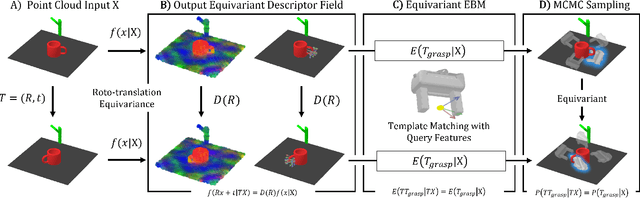

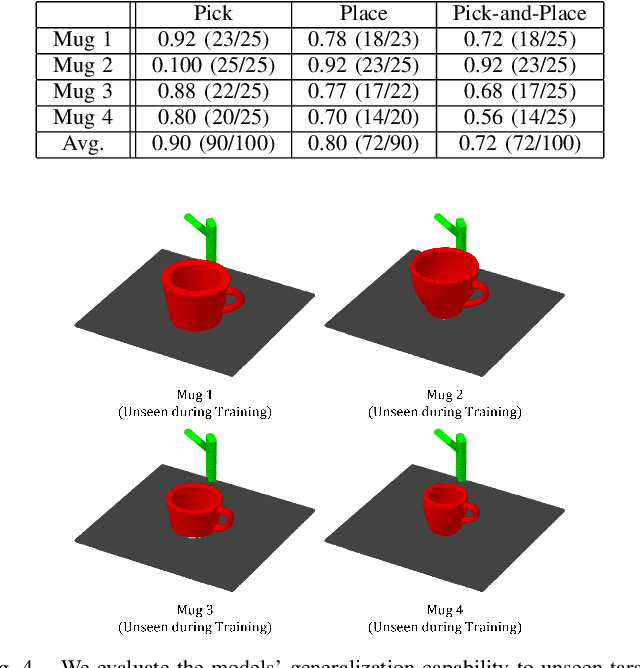
End-to-end learning for visual robotic manipulation is known to suffer from sample inefficiency, requiring a large number of demonstrations. The spatial roto-translation equivariance, or the SE(3)-equivariance can be exploited to improve the sample efficiency for learning robotic manipulation. In this paper, we present fully end-to-end SE(3)-equivariant models for visual robotic manipulation from a point cloud input. By utilizing the representation theory of the Lie group, we construct novel SE(3)-equivariant energy-based models that allow highly sample efficient end-to-end learning. We show that our models can learn from scratch without prior knowledge yet is highly sample efficient (~10 demonstrations are enough). Furthermore, we show that the trained models can generalize to tasks with (i) previously unseen target object poses, (ii) previously unseen target object instances of the category, and (iii) previously unseen visual distractors. We experiment with 6-DoF robotic manipulation tasks to validate our models' sample efficiency and generalizability. Codes are available at: https://github.com/tomato1mule/edf
Attaining Interpretability in Reinforcement Learning via Hierarchical Primitive Composition
Oct 15, 2021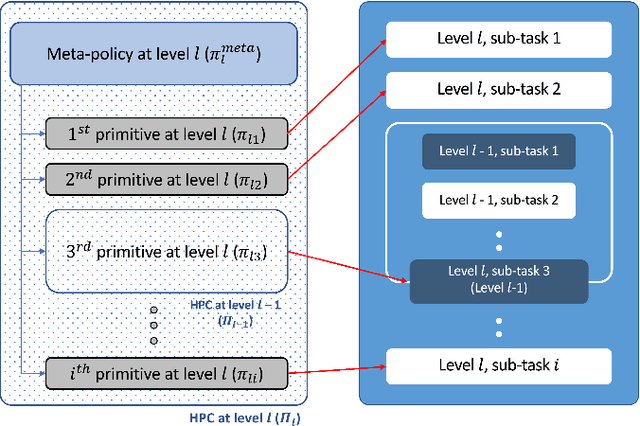


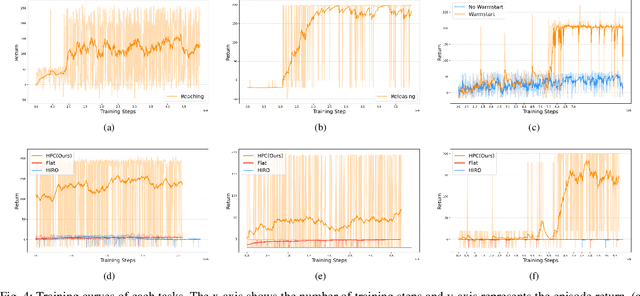
Deep reinforcement learning has shown its effectiveness in various applications and provides a promising direction for solving tasks with high complexity. In most reinforcement learning algorithms, however, two major issues need to be dealt with - the sample inefficiency and the interpretability of a policy. The former happens when the environment is sparsely rewarded and/or has a long-term credit assignment problem, while the latter becomes a problem when the learned policies are deployed at the customer side product. In this paper, we propose a novel hierarchical reinforcement learning algorithm that mitigates the aforementioned issues by decomposing the original task in a hierarchy and by compounding pretrained primitives with intents. We show how the proposed scheme can be employed in practice by solving a pick and place task with a 6 DoF manipulator.