 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttaining Interpretability in Reinforcement Learning via Hierarchical Primitive Composition
Paper and Code
Oct 15, 2021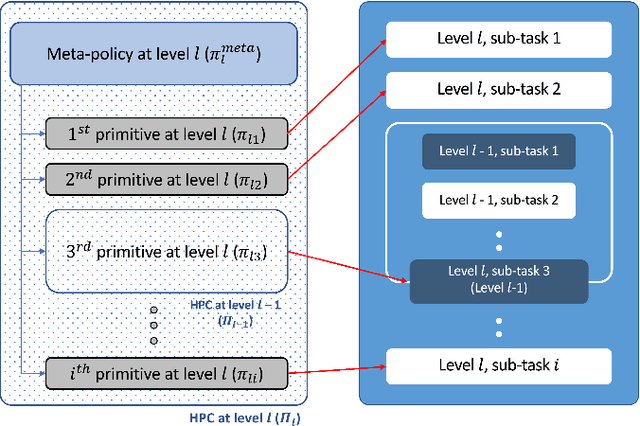


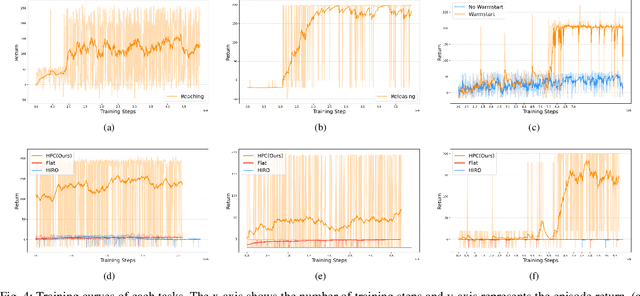
Deep reinforcement learning has shown its effectiveness in various applications and provides a promising direction for solving tasks with high complexity. In most reinforcement learning algorithms, however, two major issues need to be dealt with - the sample inefficiency and the interpretability of a policy. The former happens when the environment is sparsely rewarded and/or has a long-term credit assignment problem, while the latter becomes a problem when the learned policies are deployed at the customer side product. In this paper, we propose a novel hierarchical reinforcement learning algorithm that mitigates the aforementioned issues by decomposing the original task in a hierarchy and by compounding pretrained primitives with intents. We show how the proposed scheme can be employed in practice by solving a pick and place task with a 6 DoF manipulator.