 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modern System Recipe for Situated Embodied Human-Robot Conversation with Real-Time Multimodal LLMs and Tool-Calling
Feb 04, 2026Situated embodied conversation requires robots to interleave real-time dialogue with active perception: deciding what to look at, when to look, and what to say under tight latency constraints. We present a simple, minimal system recipe that pairs a real-time multimodal language model with a small set of tool interfaces for attention and active perception. We study six home-style scenarios that require frequent attention shifts and increasing perceptual scope. Across four system variants, we evaluate turn-level tool-decision correctness against human annotations and collect subjective ratings of interaction quality. Results indicate that real-time multimodal large language models and tool use for active perception is a promising direction for practical situated embodied conversation.
Leveraging Large Language Models to Identify Conversation Threads in Collaborative Learning
Oct 26, 2025Understanding how ideas develop and flow in small-group conversations is critical for analyzing collaborative learning. A key structural feature of these interactions is threading, the way discourse talk naturally organizes into interwoven topical strands that evolve over time. While threading has been widely studied in asynchronous text settings, detecting threads in synchronous spoken dialogue remains challenging due to overlapping turns and implicit cues. At the same time, large language models (LLMs) show promise for automating discourse analysis but often struggle with long-context tasks that depend on tracing these conversational links. In this paper, we investigate whether explicit thread linkages can improve LLM-based coding of relational moves in group talk. We contribute a systematic guidebook for identifying threads in synchronous multi-party transcripts and benchmark different LLM prompting strategies for automated threading. We then test how threading influences performance on downstream coding of conversational analysis frameworks, that capture core collaborative actions such as agreeing, building, and eliciting. Our results show that providing clear conversational thread information improves LLM coding performance and underscores the heavy reliance of downstream analysis on well-structured dialogue. We also discuss practical trade-offs in time and cost, emphasizing where human-AI hybrid approaches can yield the best value. Together, this work advances methods for combining LLMs and robust conversational thread structures to make sense of complex, real-time group interactions.
Aligning Dialogue Agents with Global Feedback via Large Language Model Reward Decomposition
May 21, 2025We propose a large language model based reward decomposition framework for aligning dialogue agents using only a single session-level feedback signal. We leverage the reasoning capabilities of a frozen, pretrained large language model (LLM) to infer fine-grained local implicit rewards by decomposing global, session-level feedback. Our first text-only variant prompts the LLM to perform reward decomposition using only the dialogue transcript. The second multimodal variant incorporates additional behavioral cues, such as pitch, gaze, and facial affect, expressed as natural language descriptions. These inferred turn-level rewards are distilled into a lightweight reward model, which we utilize for RL-based fine-tuning for dialogue generation. We evaluate both text-only and multimodal variants against state-of-the-art reward decomposition methods and demonstrate notable improvements in human evaluations of conversation quality, suggesting that LLMs are strong reward decomposers that obviate the need for manual reward shaping and granular human feedback.
Does "Reasoning" with Large Language Models Improve Recognizing, Generating, and Reframing Unhelpful Thoughts?
Mar 31, 2025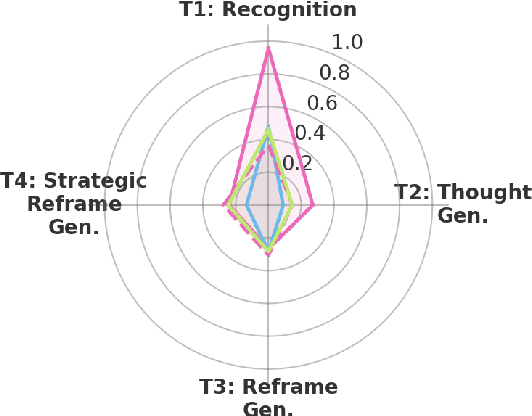
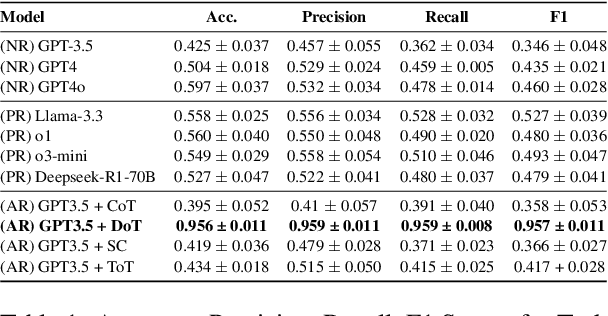
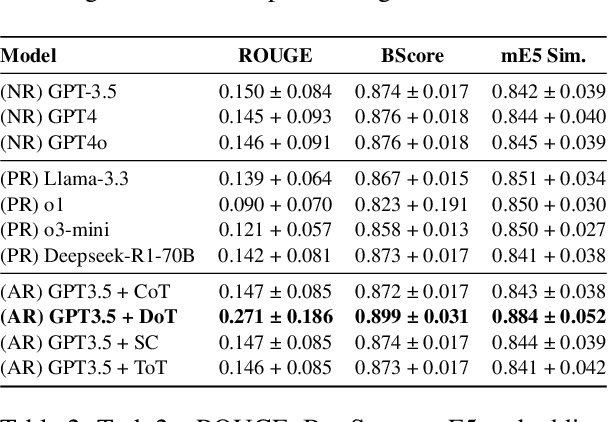
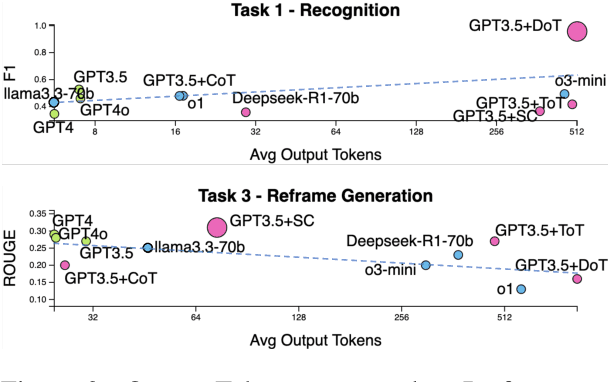
Cognitive Reframing, a core element of Cognitive Behavioral Therapy (CBT), helps individuals reinterpret negative experiences by finding positive meaning. Recent advances in Large Language Models (LLMs) have demonstrated improved performance through reasoning-based strategies. This inspires a promising direction of leveraging the reasoning capabilities of LLMs to improve CBT and mental reframing by simulating the process of critical thinking, potentially enabling more effective recognition, generation, and reframing of cognitive distortions. In this work, we investigate the role of various reasoning methods, including pre-trained reasoning LLMs and augmented reasoning strategies such as CoT and self-consistency in enhancing LLMs' ability to perform cognitive reframing tasks. We find that augmented reasoning methods, even when applied to "outdated" LLMs like GPT-3.5, consistently outperform state-of-the-art pretrained reasoning models on recognizing, generating and reframing unhelpful thoughts.
Improving Dialogue Agents by Decomposing One Global Explicit Annotation with Local Implicit Multimodal Feedback
Mar 17, 2024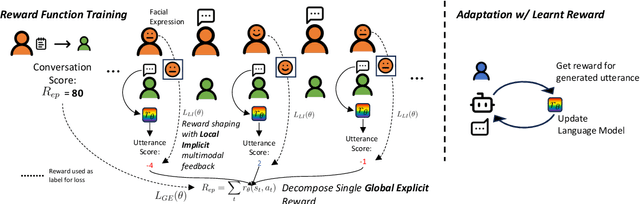
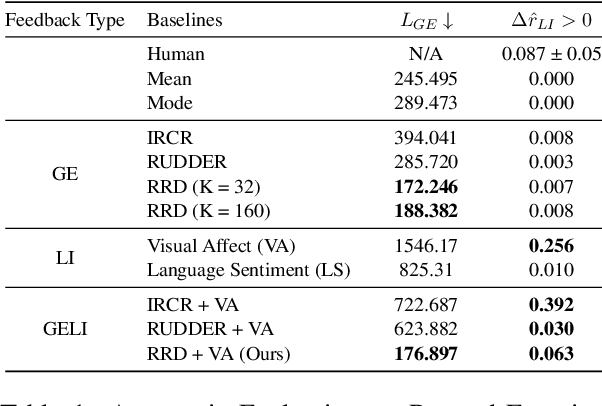
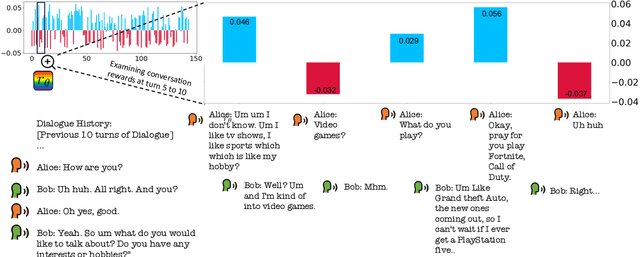

We describe an approach for aligning an LLM-based dialogue agent based on global (i.e., dialogue-level) rewards, while also taking into account naturally-occurring multimodal signals. At a high level, our approach (dubbed GELI) learns a local, turn-level reward model by decomposing the human-provided Global Explicit (GE) session-level reward, using Local Implicit (LI} multimodal reward signals to crossmodally shape the reward decomposition step. This decomposed reward model is then used as part of the standard RHLF pipeline improve an LLM-based dialog agent. We run quantitative and qualitative human studies to evaluate the performance of our GELI approach, and find that it shows consistent improvements across various conversational metrics compared to baseline methods.
HIINT: Historical, Intra- and Inter- personal Dynamics Modeling with Cross-person Memory Transformer
May 21, 2023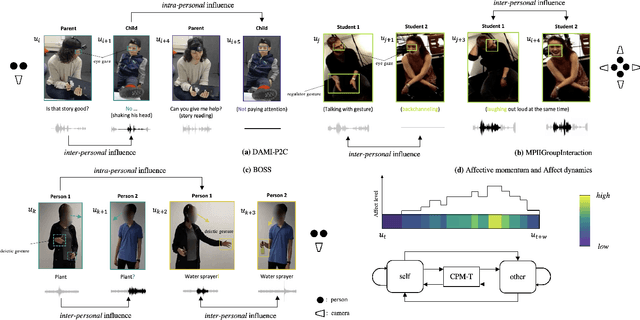
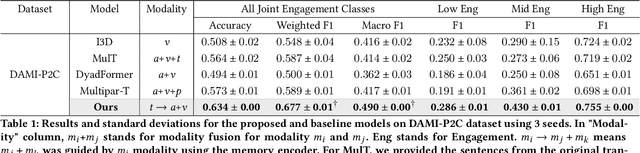
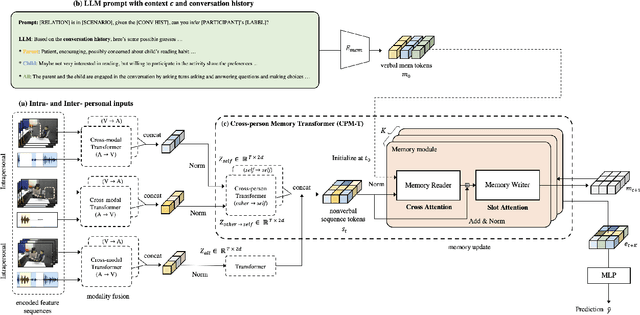
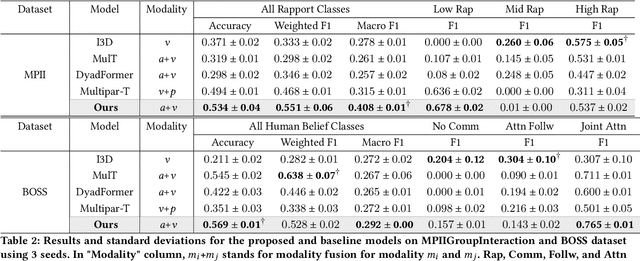
Accurately modeling affect dynamics, which refers to the changes and fluctuations in emotions and affective displays during human conversations, is crucial for understanding human interactions. By analyzing affect dynamics, we can gain insights into how people communicate, respond to different situations, and form relationships. However, modeling affect dynamics is challenging due to contextual factors, such as the complex and nuanced nature of interpersonal relationships, the situation, and other factors that influence affective displays. To address this challenge, we propose a Cross-person Memory Transformer (CPM-T) framework which is able to explicitly model affective dynamics (intrapersonal and interpersonal influences) by identifying verbal and non-verbal cues, and with a large language model to utilize the pre-trained knowledge and perform verbal reasoning. The CPM-T framework maintains memory modules to store and update the contexts within the conversation window, enabling the model to capture dependencies between earlier and later parts of a conversation. Additionally, our framework employs cross-modal attention to effectively align information from multi-modalities and leverage cross-person attention to align behaviors in multi-party interactions. We evaluate the effectiveness and generalizability of our approach on three publicly available datasets for joint engagement, rapport, and human beliefs prediction tasks. Remarkably, the CPM-T framework outperforms baseline models in average F1-scores by up to 7.3%, 9.3%, and 2.0% respectively. Finally, we demonstrate the importance of each component in the framework via ablation studies with respect to multimodal temporal behavior.
Multipar-T: Multiparty-Transformer for Capturing Contingent Behaviors in Group Conversations
Apr 19, 2023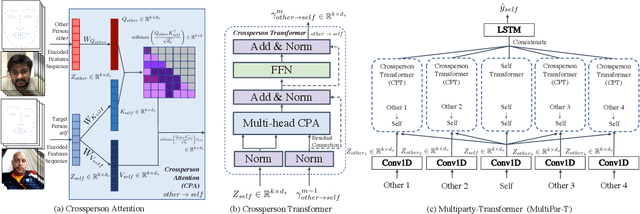
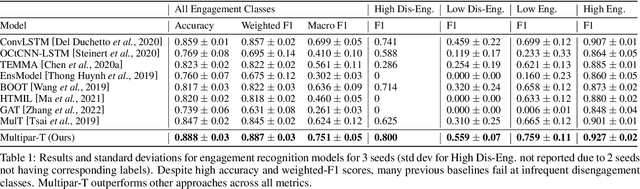
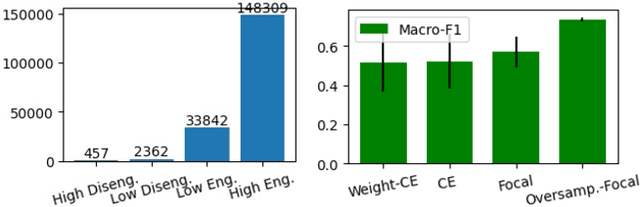

As we move closer to real-world AI systems, AI agents must be able to deal with multiparty (group) conversations. Recognizing and interpreting multiparty behaviors is challenging, as the system must recognize individual behavioral cues, deal with the complexity of multiple streams of data from multiple people, and recognize the subtle contingent social exchanges that take place amongst group members. To tackle this challenge, we propose the Multiparty-Transformer (Multipar-T), a transformer model for multiparty behavior modeling. The core component of our proposed approach is the Crossperson Attention, which is specifically designed to detect contingent behavior between pairs of people. We verify the effectiveness of Multipar-T on a publicly available video-based group engagement detection benchmark, where it outperforms state-of-the-art approaches in average F-1 scores by 5.2% and individual class F-1 scores by up to 10.0%. Through qualitative analysis, we show that our Crossperson Attention module is able to discover contingent behavior.
Multimodal Lecture Presentations Dataset: Understanding Multimodality in Educational Slides
Aug 17, 2022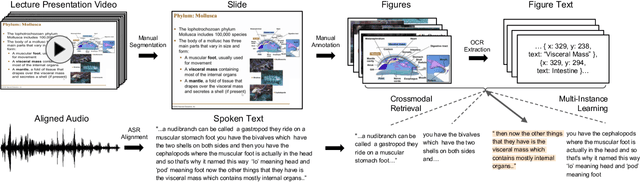
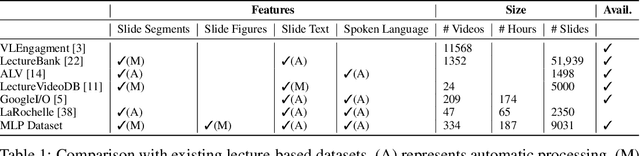
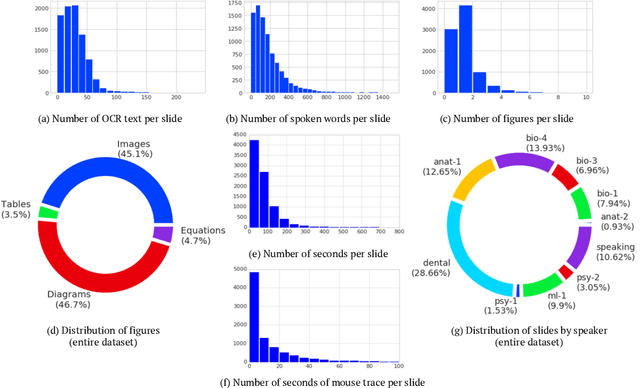
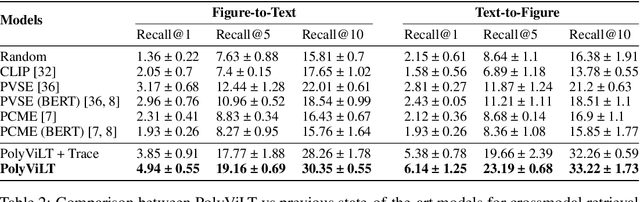
Lecture slide presentations, a sequence of pages that contain text and figures accompanied by speech, are constructed and presented carefully in order to optimally transfer knowledge to students. Previous studies in multimedia and psychology attribute the effectiveness of lecture presentations to their multimodal nature. As a step toward developing AI to aid in student learning as intelligent teacher assistants, we introduce the Multimodal Lecture Presentations dataset as a large-scale benchmark testing the capabilities of machine learning models in multimodal understanding of educational content. Our dataset contains aligned slides and spoken language, for 180+ hours of video and 9000+ slides, with 10 lecturers from various subjects (e.g., computer science, dentistry, biology). We introduce two research tasks which are designed as stepping stones towards AI agents that can explain (automatically captioning a lecture presentation) and illustrate (synthesizing visual figures to accompany spoken explanations) educational content. We provide manual annotations to help implement these two research tasks and evaluate state-of-the-art models on them. Comparing baselines and human student performances, we find that current models struggle in (1) weak crossmodal alignment between slides and spoken text, (2) learning novel visual mediums, (3) technical language, and (4) long-range sequences. Towards addressing this issue, we also introduce PolyViLT, a multimodal transformer trained with a multi-instance learning loss that is more effective than current approaches. We conclude by shedding light on the challenges and opportunities in multimodal understanding of educational presentations.
Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional-Mixture Approach
Jul 24, 2020

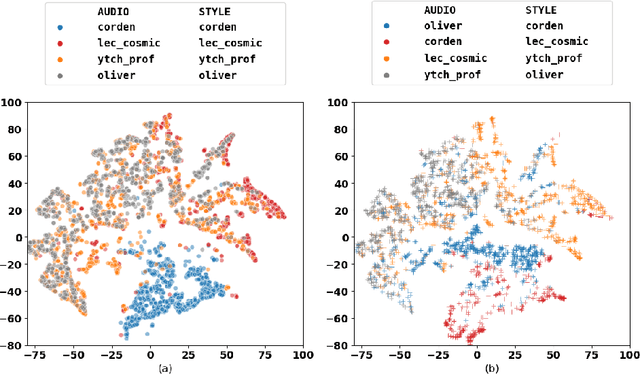
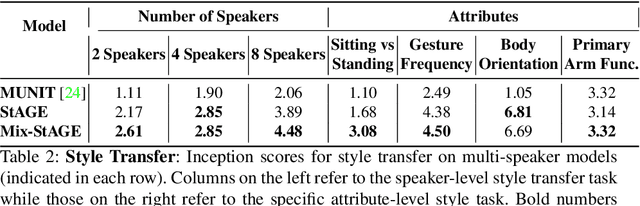
How can we teach robots or virtual assistants to gesture naturally? Can we go further and adapt the gesturing style to follow a specific speaker? Gestures that are naturally timed with corresponding speech during human communication are called co-speech gestures. A key challenge, called gesture style transfer, is to learn a model that generates these gestures for a speaking agent 'A' in the gesturing style of a target speaker 'B'. A secondary goal is to simultaneously learn to generate co-speech gestures for multiple speakers while remembering what is unique about each speaker. We call this challenge style preservation. In this paper, we propose a new model, named Mix-StAGE, which trains a single model for multiple speakers while learning unique style embeddings for each speaker's gestures in an end-to-end manner. A novelty of Mix-StAGE is to learn a mixture of generative models which allows for conditioning on the unique gesture style of each speaker. As Mix-StAGE disentangles style and content of gestures, gesturing styles for the same input speech can be altered by simply switching the style embeddings. Mix-StAGE also allows for style preservation when learning simultaneously from multiple speakers. We also introduce a new dataset, Pose-Audio-Transcript-Style (PATS), designed to study gesture generation and style transfer. Our proposed Mix-StAGE model significantly outperforms the previous state-of-the-art approach for gesture generation and provides a path towards performing gesture style transfer across multiple speakers. Link to code, data, and videos: http://chahuja.com/mix-stage
* 24 pages, 12 figures