 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenButler: Token Importance is Predictable
Mar 10, 2025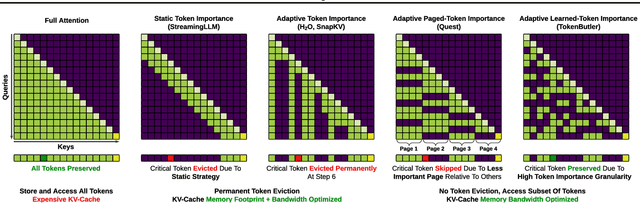
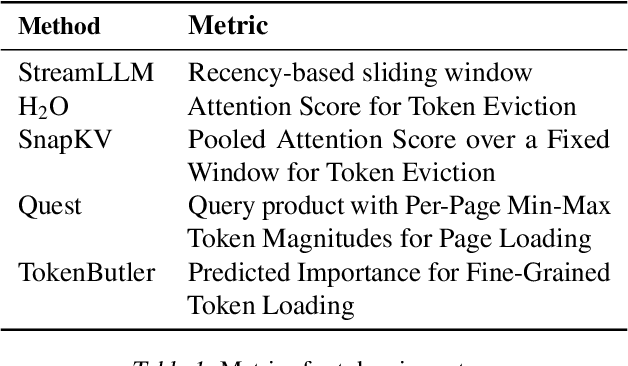
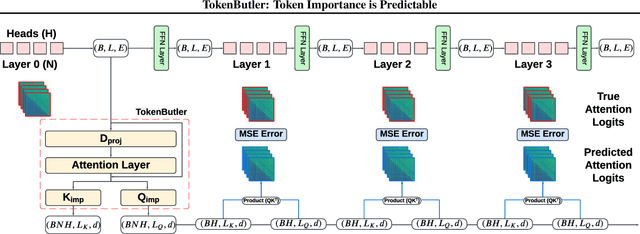
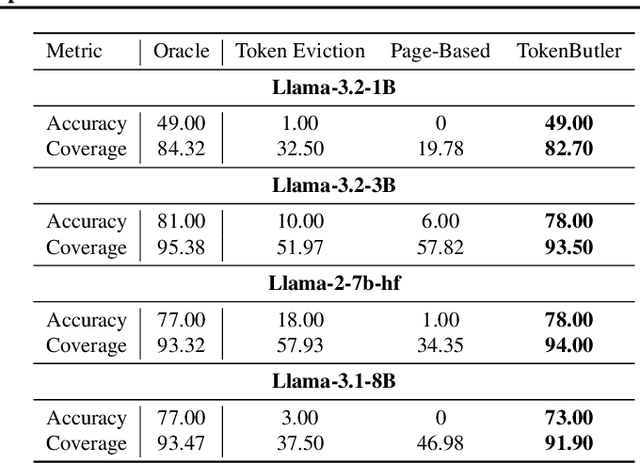
Large Language Models (LLMs) rely on the Key-Value (KV) Cache to store token history, enabling efficient decoding of tokens. As the KV-Cache grows, it becomes a major memory and computation bottleneck, however, there is an opportunity to alleviate this bottleneck, especially because prior research has shown that only a small subset of tokens contribute meaningfully to each decoding step. A key challenge in finding these critical tokens is that they are dynamic, and heavily input query-dependent. Existing methods either risk quality by evicting tokens permanently, or retain the full KV-Cache but rely on retrieving chunks (pages) of tokens at generation, failing at dense, context-rich tasks. Additionally, many existing KV-Cache sparsity methods rely on inaccurate proxies for token importance. To address these limitations, we introduce TokenButler, a high-granularity, query-aware predictor that learns to identify these critical tokens. By training a light-weight predictor with less than 1.2% parameter overhead, TokenButler prioritizes tokens based on their contextual, predicted importance. This improves perplexity & downstream accuracy by over 8% relative to SoTA methods for estimating token importance. We evaluate TokenButler on a novel synthetic small-context co-referential retrieval task, demonstrating near-oracle accuracy. Code, models and benchmarks: https://github.com/abdelfattah-lab/TokenButler
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Jun 24, 2024



The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20\% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at \href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.