 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models
Jan 28, 2025



Large pre-trained models have achieved outstanding results in sequence modeling. The Transformer block and its attention mechanism have been the main drivers of the success of these models. Recently, alternative architectures, such as Selective Structured State Space Models (SSMs), have been proposed to address the inefficiencies of Transformers. This paper explores the compression of SSM-based models, particularly Mamba and its hybrids. We study the sensitivity of these models to the removal of selected components at different granularities to reduce the model size and computational overhead, thus improving their efficiency while maintaining accuracy. The proposed solutions, collectively referred to as Mamba-Shedder, achieve a speedup of up to 1.4x during inference, demonstrating that model efficiency can be improved by eliminating several redundancies with minimal impact on the overall model performance. The code is available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
MultiPruner: Balanced Structure Removal in Foundation Models
Jan 17, 2025



Recently, state-of-the-art approaches for pruning large pre-trained models (LPMs) have demonstrated that the training-free removal of non-critical residual blocks in Transformers is viable for reducing model size, achieving results that outperform previous training-free pruning approaches. Motivated by these findings, we extend BlockPruner (Zhong et al., 2024) and propose MultiPruner, a pruning approach that surpasses recent training-free pruning methods by adopting a multidimensional, iterative, fine-grained pruning strategy. In MultiPruner, multidimensional pruning reinstates the structural balance in block-pruned models by sequentially compressing along three dimensions: i) residual blocks, ii) channels of multilayer perceptrons (MLP), and iii) attention heads. This solution enhances zero-shot accuracy on downstream tasks compared to other techniques while improving model compression ratios, producing compressed models with fewer computing and memory requirements. Extensive experiments demonstrate the advantages of the proposed method across various large pre-trained models. The code and pruning configurations are available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
SQFT: Low-cost Model Adaptation in Low-precision Sparse Foundation Models
Oct 01, 2024Large pre-trained models (LPMs), such as large language models, have become ubiquitous and are employed in many applications. These models are often adapted to a desired domain or downstream task through a fine-tuning stage. This paper proposes SQFT, an end-to-end solution for low-precision sparse parameter-efficient fine-tuning of LPMs, allowing for effective model manipulation in resource-constrained environments. Additionally, an innovative strategy enables the merging of sparse weights with low-rank adapters without losing sparsity and accuracy, overcoming the limitations of previous approaches. SQFT also addresses the challenge of having quantized weights and adapters with different numerical precisions, enabling merging in the desired numerical format without sacrificing accuracy. Multiple adaptation scenarios, models, and comprehensive sparsity levels demonstrate the effectiveness of SQFT. Models and code are available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
Shears: Unstructured Sparsity with Neural Low-rank Adapter Search
Apr 16, 2024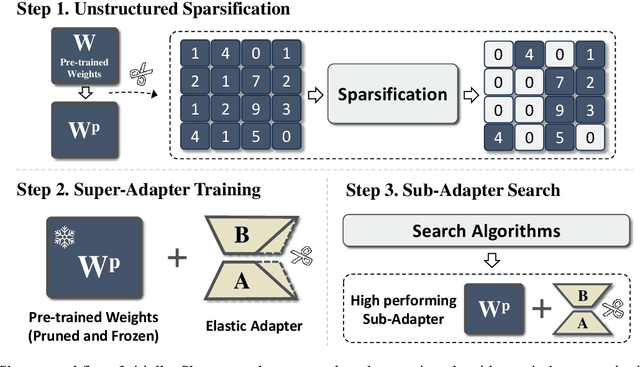
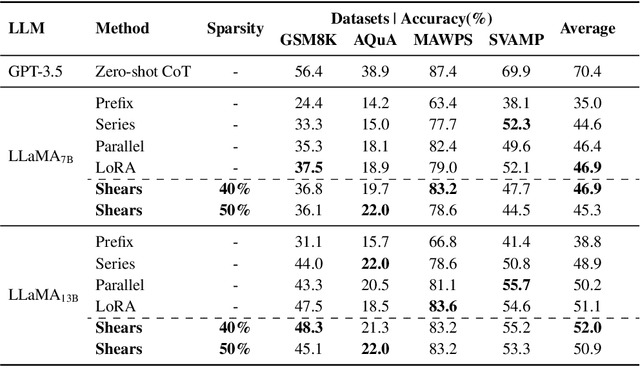

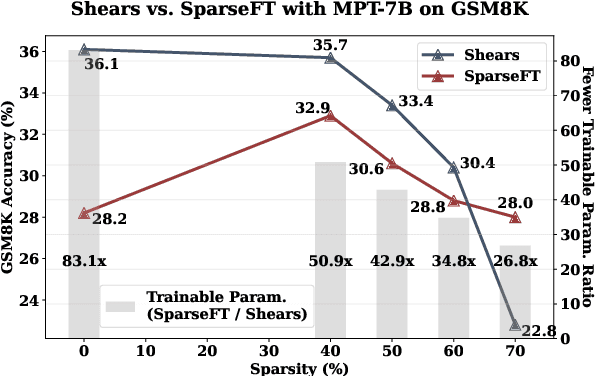
Recently, several approaches successfully demonstrated that weight-sharing Neural Architecture Search (NAS) can effectively explore a search space of elastic low-rank adapters (LoRA), allowing the parameter-efficient fine-tuning (PEFT) and compression of large language models. In this paper, we introduce a novel approach called Shears, demonstrating how the integration of cost-effective sparsity and a proposed Neural Low-rank adapter Search (NLS) algorithm can further improve the efficiency of PEFT approaches. Results demonstrate the benefits of Shears compared to other methods, reaching high sparsity levels while improving or with little drop in accuracy, utilizing a single GPU for a pair of hours.
SADGA: Structure-Aware Dual Graph Aggregation Network for Text-to-SQL
Nov 01, 2021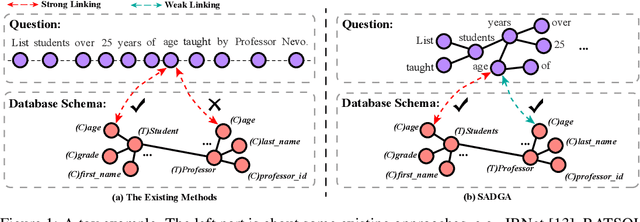
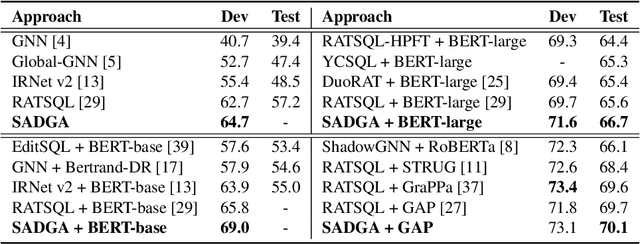
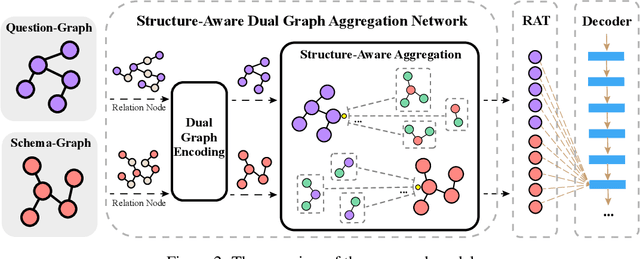
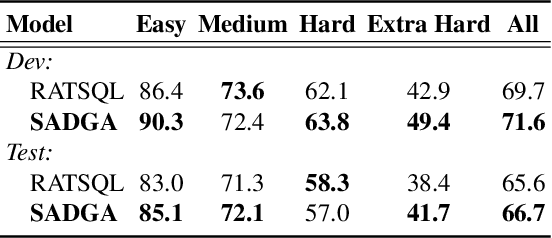
The Text-to-SQL task, aiming to translate the natural language of the questions into SQL queries, has drawn much attention recently. One of the most challenging problems of Text-to-SQL is how to generalize the trained model to the unseen database schemas, also known as the cross-domain Text-to-SQL task. The key lies in the generalizability of (i) the encoding method to model the question and the database schema and (ii) the question-schema linking method to learn the mapping between words in the question and tables/columns in the database schema. Focusing on the above two key issues, we propose a Structure-Aware Dual Graph Aggregation Network (SADGA) for cross-domain Text-to-SQL. In SADGA, we adopt the graph structure to provide a unified encoding model for both the natural language question and database schema. Based on the proposed unified modeling, we further devise a structure-aware aggregation method to learn the mapping between the question-graph and schema-graph. The structure-aware aggregation method is featured with Global Graph Linking, Local Graph Linking, and Dual-Graph Aggregation Mechanism. We not only study the performance of our proposal empirically but also achieved 3rd place on the challenging Text-to-SQL benchmark Spider at the time of writing.