 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplexNet: Towards Fully Satisfied Logical Constraints in Neural Networks
Nov 02, 2021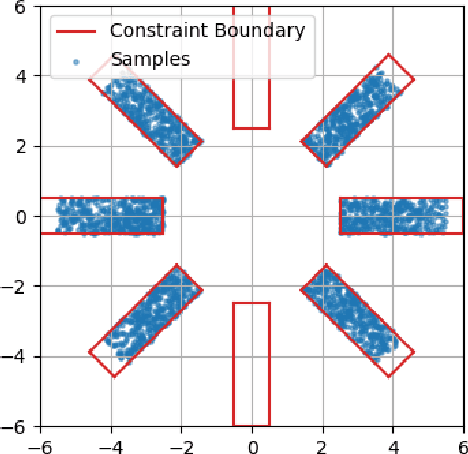
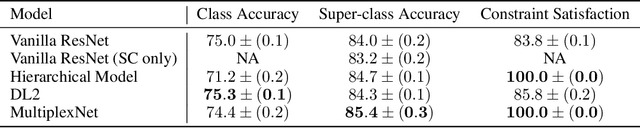
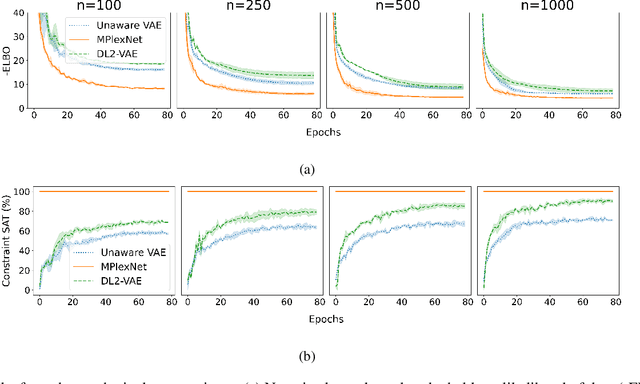

We propose a novel way to incorporate expert knowledge into the training of deep neural networks. Many approaches encode domain constraints directly into the network architecture, requiring non-trivial or domain-specific engineering. In contrast, our approach, called MultiplexNet, represents domain knowledge as a logical formula in disjunctive normal form (DNF) which is easy to encode and to elicit from human experts. It introduces a Categorical latent variable that learns to choose which constraint term optimizes the error function of the network and it compiles the constraints directly into the output of existing learning algorithms. We demonstrate the efficacy of this approach empirically on several classical deep learning tasks, such as density estimation and classification in both supervised and unsupervised settings where prior knowledge about the domains was expressed as logical constraints. Our results show that the MultiplexNet approach learned to approximate unknown distributions well, often requiring fewer data samples than the alternative approaches. In some cases, MultiplexNet finds better solutions than the baselines; or solutions that could not be achieved with the alternative approaches. Our contribution is in encoding domain knowledge in a way that facilitates inference that is shown to be both efficient and general; and critically, our approach guarantees 100% constraint satisfaction in a network's output.
The Goal-Gradient Hypothesis in Stack Overflow
Feb 14, 2020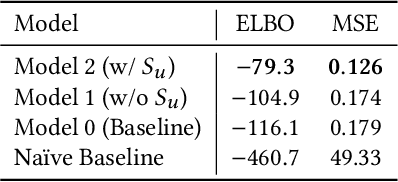
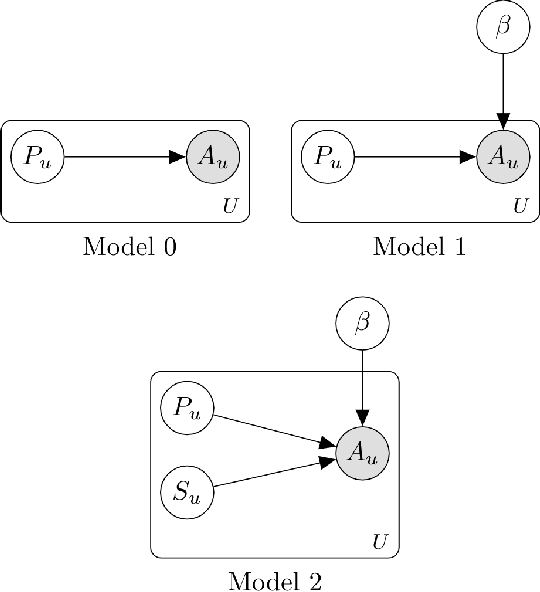

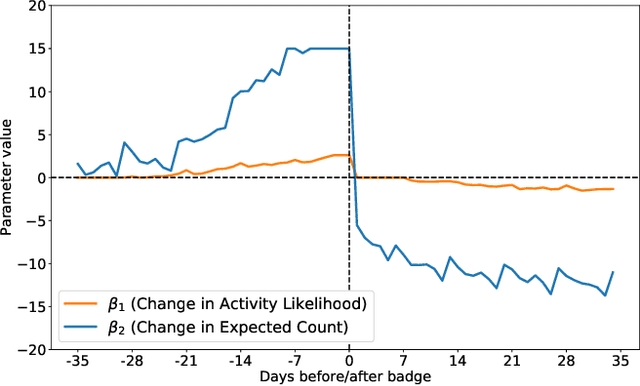
According to the goal-gradient hypothesis, people increase their efforts toward a reward as they close in on the reward. This hypothesis has recently been used to explain users' behavior in online communities that use badges as rewards for completing specific activities. In such settings, users exhibit a "steering effect," a dramatic increase in activity as the users approach a badge threshold, thereby following the predictions made by the goal-gradient hypothesis. This paper provides a new probabilistic model of users' behavior, which captures users who exhibit different levels of steering. We apply this model to data from the popular Q&A site, Stack Overflow, and study users who achieve one of the badges available on this platform. Our results show that only a fraction (20%) of all users strongly experience steering, whereas the activity of more than 40% of badge achievers appears not to be affected by the badge. In particular, we find that for some of the population, an increased activity in and around the badge acquisition date may reflect a statistical artifact rather than steering, as was previously thought in prior work. These results are important for system designers who hope to motivate and guide their users towards certain actions. We have highlighted the need for further studies which investigate what motivations drive the non-steered users to contribute to online communities.
Interpretable Models of Human Interaction in Immersive Simulation Settings
Sep 24, 2019
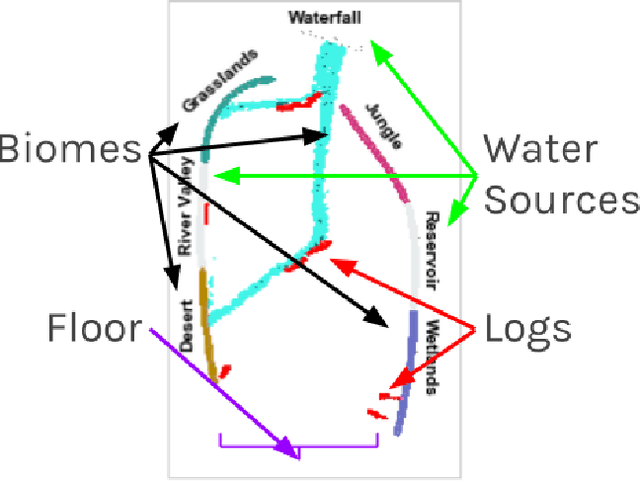
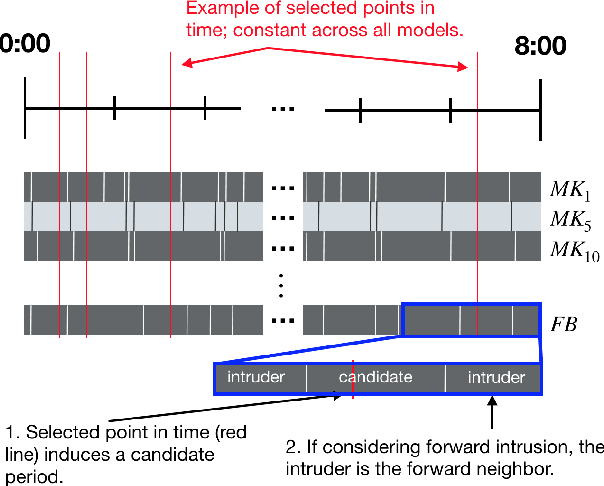
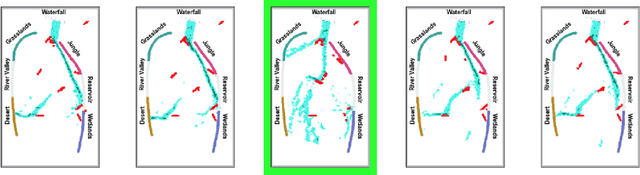
Immersive simulations are increasingly used for teaching and training in many societally important arenas including healthcare, disaster response and science education. The interactions of participants in such settings lead to a complex array of emergent outcomes that present challenges for analysis. This paper studies a central element of such an analysis, namely the interpretability of models for inferring structure in time series data. This problem is explored in the context of modeling student interactions in an immersive ecological-system simulation. Unsupervised machine learning is applied to data on system dynamics with the aim of helping teachers determine the effects of students' actions on these dynamics. We address the question of choosing the optimal machine learning model, considering both statistical information criteria and interpretabilty quality. Our approach adapts two interpretability tests from the literature that measure the agreement between the model output and human judgment. The results of a user study show that the models that are the best understood by people are not those that optimize information theoretic criteria. In addition, a model using a fully Bayesian approach performed well on both statistical measures and on human-subject tests of interpretabilty, making it a good candidate for automated model selection that does not require human-in-the-loop evaluation. The results from this paper are already being used in the classroom and can inform the design of interpretable models for a broad range of socially relevant domains.