 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Hatred: Efficient Multimodal Detection of Hatemongers
Jun 24, 2025Automatic detection of online hate speech serves as a crucial step in the detoxification of the online discourse. Moreover, accurate classification can promote a better understanding of the proliferation of hate as a social phenomenon. While most prior work focus on the detection of hateful utterances, we argue that focusing on the user level is as important, albeit challenging. In this paper we consider a multimodal aggregative approach for the detection of hate-mongers, taking into account the potentially hateful texts, user activity, and the user network. Evaluating our method on three unique datasets X (Twitter), Gab, and Parler we show that processing a user's texts in her social context significantly improves the detection of hate mongers, compared to previously used text and graph-based methods. We offer comprehensive set of results obtained in different experimental settings as well as qualitative analysis of illustrative cases. Our method can be used to improve the classification of coded messages, dog-whistling, and racial gas-lighting, as well as to inform intervention measures. Moreover, we demonstrate that our multimodal approach performs well across very different content platforms and over large datasets and networks.
A Test of Time: Predicting the Sustainable Success of Online Collaboration in Wikipedia
Oct 24, 2024The Internet has significantly expanded the potential for global collaboration, allowing millions of users to contribute to collective projects like Wikipedia. While prior work has assessed the success of online collaborations, most approaches are time-agnostic, evaluating success without considering its longevity. Research on the factors that ensure the long-term preservation of high-quality standards in online collaboration is scarce. In this study, we address this gap. We propose a novel metric, `Sustainable Success,' which measures the ability of collaborative efforts to maintain their quality over time. Using Wikipedia as a case study, we introduce the SustainPedia dataset, which compiles data from over 40K Wikipedia articles, including each article's sustainable success label and more than 300 explanatory features such as edit history, user experience, and team composition. Using this dataset, we develop machine learning models to predict the sustainable success of Wikipedia articles. Our best-performing model achieves a high AU-ROC score of 0.88 on average. Our analysis reveals important insights. For example, we find that the longer an article takes to be recognized as high-quality, the more likely it is to maintain that status over time (i.e., be sustainable). Additionally, user experience emerged as the most critical predictor of sustainability. Our analysis provides insights into broader collective actions beyond Wikipedia (e.g., online activism, crowdsourced open-source software), where the same social dynamics that drive success on Wikipedia might play a role. We make all data and code used for this study publicly available for further research.
AggregHate: An Efficient Aggregative Approach for the Detection of Hatemongers on Social Platforms
Sep 22, 2024Automatic detection of online hate speech serves as a crucial step in the detoxification of the online discourse. Moreover, accurate classification can promote a better understanding of the proliferation of hate as a social phenomenon. While most prior work focus on the detection of hateful utterances, we argue that focusing on the user level is as important, albeit challenging. In this paper we consider a multimodal aggregative approach for the detection of hate-mongers, taking into account the potentially hateful texts, user activity, and the user network. We evaluate our methods on three unique datasets X (Twitter), Gab, and Parler showing that a processing a user's texts in her social context significantly improves the detection of hate mongers, compared to previously used text and graph-based methods. Our method can be then used to improve the classification of coded messages, dog-whistling, and racial gas-lighting, as well as inform intervention measures. Moreover, our approach is highly efficient even for very large datasets and networks.
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
With Flying Colors: Predicting Community Success in Large-scale Collaborative Campaigns
Jul 18, 2023

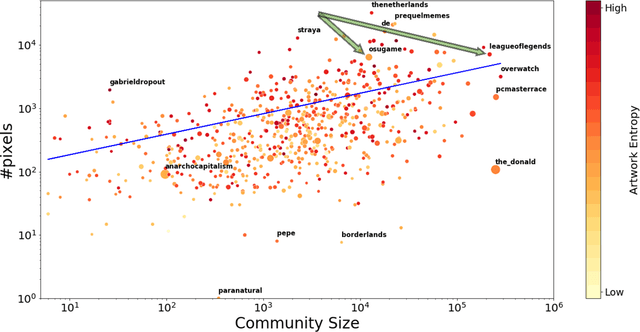

Online communities develop unique characteristics, establish social norms, and exhibit distinct dynamics among their members. Activity in online communities often results in concrete ``off-line'' actions with a broad societal impact (e.g., political street protests and norms related to sexual misconduct). While community dynamics, information diffusion, and online collaborations have been widely studied in the past two decades, quantitative studies that measure the effectiveness of online communities in promoting their agenda are scarce. In this work, we study the correspondence between the effectiveness of a community, measured by its success level in a competitive online campaign, and the underlying dynamics between its members. To this end, we define a novel task: predicting the success level of online communities in Reddit's r/place - a large-scale distributed experiment that required collaboration between community members. We consider an array of definitions for success level; each is geared toward different aspects of collaborative achievement. We experiment with several hybrid models, combining various types of features. Our models significantly outperform all baseline models over all definitions of `success level'. Analysis of the results and the factors that contribute to the success of coordinated campaigns can provide a better understanding of the resilience or the vulnerability of communities to online social threats such as election interference or anti-science trends. We make all data used for this study publicly available for further research.
This Must Be the Place: Predicting Engagement of Online Communities in a Large-scale Distributed Campaign
Feb 06, 2022
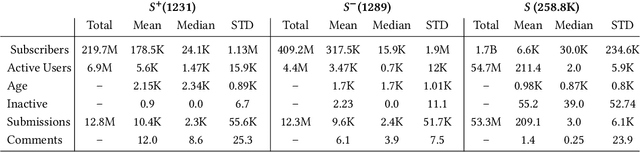
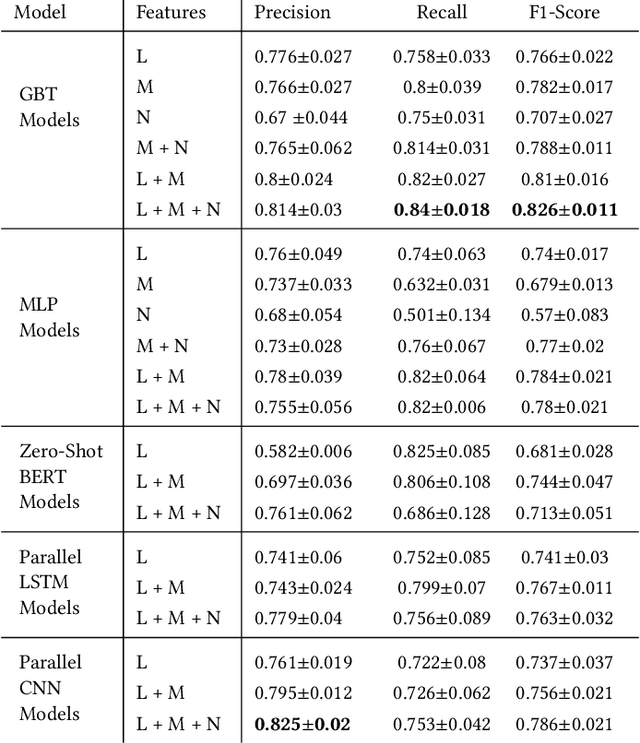
Understanding collective decision making at a large-scale, and elucidating how community organization and community dynamics shape collective behavior are at the heart of social science research. In this work we study the behavior of thousands of communities with millions of active members. We define a novel task: predicting which community will undertake an unexpected, large-scale, distributed campaign. To this end, we develop a hybrid model, combining textual cues, community meta-data, and structural properties. We show how this multi-faceted model can accurately predict large-scale collective decision-making in a distributed environment. We demonstrate the applicability of our model through Reddit's r/place - a large-scale online experiment in which millions of users, self-organized in thousands of communities, clashed and collaborated in an effort to realize their agenda. Our hybrid model achieves a high F1 prediction score of 0.826. We find that coarse meta-features are as important for prediction accuracy as fine-grained textual cues, while explicit structural features play a smaller role. Interpreting our model, we provide and support various social insights about the unique characteristics of the communities that participated in the \r/place experiment. Our results and analysis shed light on the complex social dynamics that drive collective behavior, and on the factors that propel user coordination. The scale and the unique conditions of the \rp~experiment suggest that our findings may apply in broader contexts, such as online activism, (countering) the spread of hate speech and reducing political polarization. The broader applicability of the model is demonstrated through an extensive analysis of the WallStreetBets community, their role in r/place and four years later, in the GameStop short squeeze campaign of 2021.
Going Extreme: Comparative Analysis of Hate Speech in Parler and Gab
Jan 27, 2022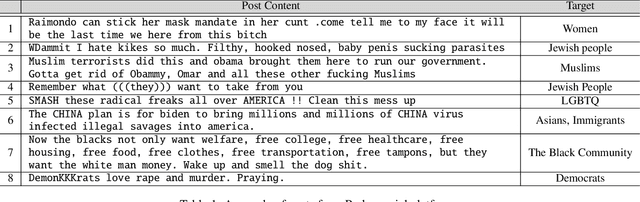

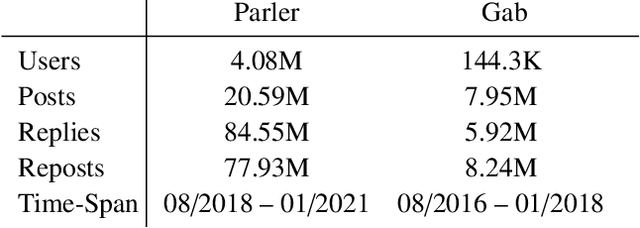
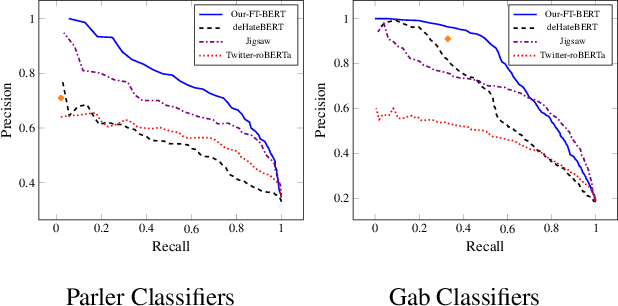
Social platforms such as Gab and Parler, branded as `free-speech' networks, have seen a significant growth of their user base in recent years. This popularity is mainly attributed to the stricter moderation enforced by mainstream platforms such as Twitter, Facebook, and Reddit. In this work we provide the first large scale analysis of hate-speech on Parler. We experiment with an array of algorithms for hate-speech detection, demonstrating limitations of transfer learning in that domain, given the illusive and ever changing nature of the ways hate-speech is delivered. In order to improve classification accuracy we annotated 10K Parler posts, which we use to fine-tune a BERT classifier. Classification of individual posts is then leveraged for the classification of millions of users via label propagation over the social network. Classifying users by their propensity to disseminate hate, we find that hate mongers make 16.1\% of Parler active users, and that they have distinct characteristics comparing to other user groups. We find that hate mongers are more active, more central and express distinct levels of sentiment and convey a distinct array of emotions like anger and sadness. We further complement our analysis by comparing the trends discovered in Parler and those found in Gab. To the best of our knowledge, this is among the first works to analyze hate speech in Parler in a quantitative manner and on the user level, and the first annotated dataset to be made available to the community.