 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Sparse Linear Regression with Sublinear Communication
Sep 15, 2022
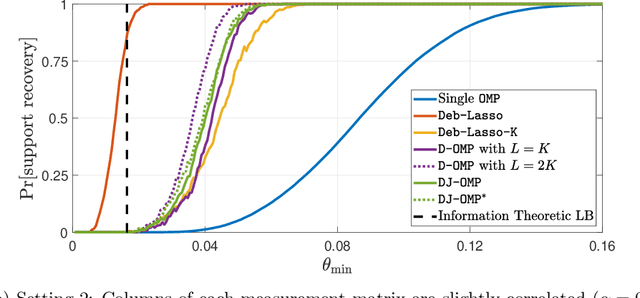
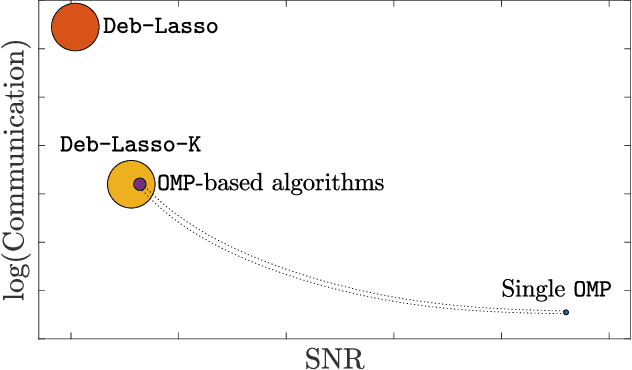
We study the problem of high-dimensional sparse linear regression in a distributed setting under both computational and communication constraints. Specifically, we consider a star topology network whereby several machines are connected to a fusion center, with whom they can exchange relatively short messages. Each machine holds noisy samples from a linear regression model with the same unknown sparse $d$-dimensional vector of regression coefficients $\theta$. The goal of the fusion center is to estimate the vector $\theta$ and its support using few computations and limited communication at each machine. In this work, we consider distributed algorithms based on Orthogonal Matching Pursuit (OMP) and theoretically study their ability to exactly recover the support of $\theta$. We prove that under certain conditions, even at low signal-to-noise-ratios where individual machines are unable to detect the support of $\theta$, distributed-OMP methods correctly recover it with total communication sublinear in $d$. In addition, we present simulations that illustrate the performance of distributed OMP-based algorithms and show that they perform similarly to more sophisticated and computationally intensive methods, and in some cases even outperform them.
Sparse Normal Means Estimation with Sublinear Communication
Feb 05, 2021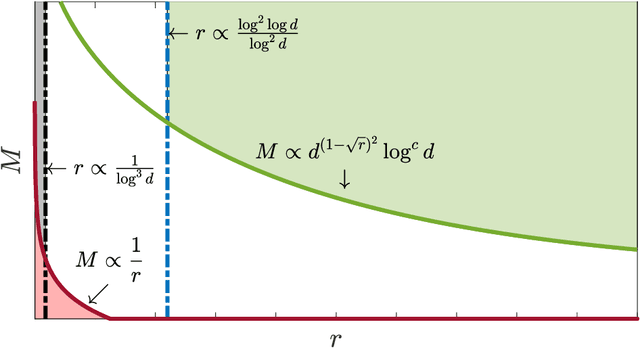
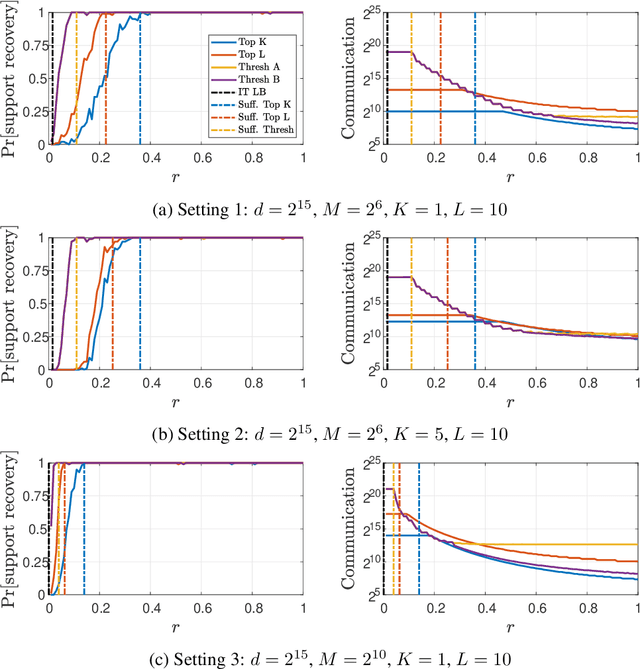
We consider the problem of sparse normal means estimation in a distributed setting with communication constraints. We assume there are $M$ machines, each holding a $d$-dimensional observation of a $K$-sparse vector $\mu$ corrupted by additive Gaussian noise. A central fusion machine is connected to the $M$ machines in a star topology, and its goal is to estimate the vector $\mu$ with a low communication budget. Previous works have shown that to achieve the centralized minimax rate for the $\ell_2$ risk, the total communication must be high - at least linear in the dimension $d$. This phenomenon occurs, however, at very weak signals. We show that once the signal-to-noise ratio (SNR) is slightly higher, the support of $\mu$ can be correctly recovered with much less communication. Specifically, we present two algorithms for the distributed sparse normal means problem, and prove that above a certain SNR threshold, with high probability, they recover the correct support with total communication that is sublinear in the dimension $d$. Furthermore, the communication decreases exponentially as a function of signal strength. If in addition $KM\ll d$, then with an additional round of sublinear communication, our algorithms achieve the centralized rate for the $\ell_2$ risk. Finally, we present simulations that illustrate the performance of our algorithms in different parameter regimes.
Efficient Regression in Metric Spaces via Approximate Lipschitz Extension
Apr 24, 2017We present a framework for performing efficient regression in general metric spaces. Roughly speaking, our regressor predicts the value at a new point by computing a Lipschitz extension --- the smoothest function consistent with the observed data --- after performing structural risk minimization to avoid overfitting. We obtain finite-sample risk bounds with minimal structural and noise assumptions, and a natural speed-precision tradeoff. The offline (learning) and online (prediction) stages can be solved by convex programming, but this naive approach has runtime complexity $O(n^3)$, which is prohibitive for large datasets. We design instead a regression algorithm whose speed and generalization performance depend on the intrinsic dimension of the data, to which the algorithm adapts. While our main innovation is algorithmic, the statistical results may also be of independent interest.
Do semidefinite relaxations solve sparse PCA up to the information limit?
Jun 03, 2015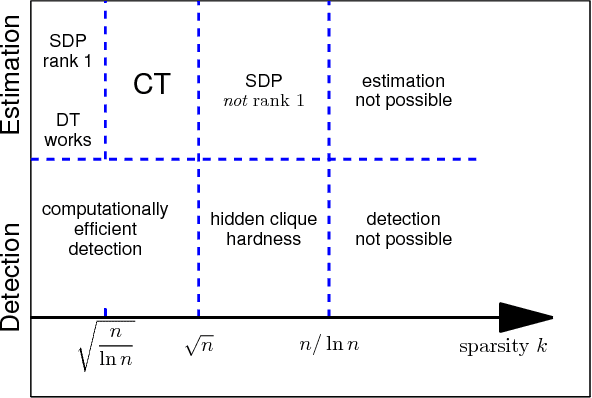
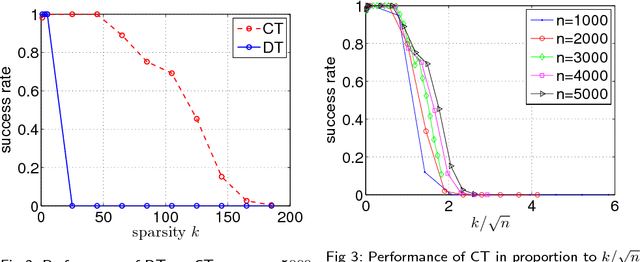
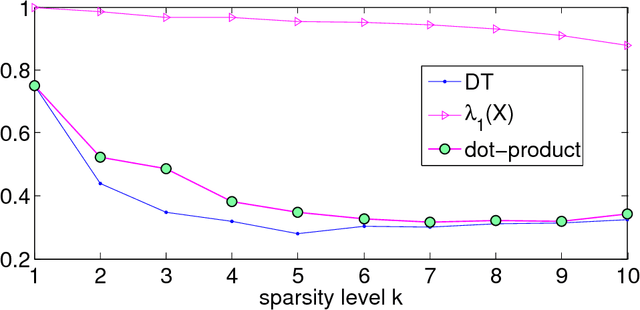
Estimating the leading principal components of data, assuming they are sparse, is a central task in modern high-dimensional statistics. Many algorithms were developed for this sparse PCA problem, from simple diagonal thresholding to sophisticated semidefinite programming (SDP) methods. A key theoretical question is under what conditions can such algorithms recover the sparse principal components? We study this question for a single-spike model with an $\ell_0$-sparse eigenvector, in the asymptotic regime as dimension $p$ and sample size $n$ both tend to infinity. Amini and Wainwright [Ann. Statist. 37 (2009) 2877-2921] proved that for sparsity levels $k\geq\Omega(n/\log p)$, no algorithm, efficient or not, can reliably recover the sparse eigenvector. In contrast, for $k\leq O(\sqrt{n/\log p})$, diagonal thresholding is consistent. It was further conjectured that an SDP approach may close this gap between computational and information limits. We prove that when $k\geq\Omega(\sqrt{n})$, the proposed SDP approach, at least in its standard usage, cannot recover the sparse spike. In fact, we conjecture that in the single-spike model, no computationally-efficient algorithm can recover a spike of $\ell_0$-sparsity $k\geq\Omega(\sqrt{n})$. Finally, we present empirical results suggesting that up to sparsity levels $k=O(\sqrt{n})$, recovery is possible by a simple covariance thresholding algorithm.
* Published at http://dx.doi.org/10.1214/15-AOS1310 in the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Adaptive Metric Dimensionality Reduction
Mar 25, 2015We study adaptive data-dependent dimensionality reduction in the context of supervised learning in general metric spaces. Our main statistical contribution is a generalization bound for Lipschitz functions in metric spaces that are doubling, or nearly doubling. On the algorithmic front, we describe an analogue of PCA for metric spaces: namely an efficient procedure that approximates the data's intrinsic dimension, which is often much lower than the ambient dimension. Our approach thus leverages the dual benefits of low dimensionality: (1) more efficient algorithms, e.g., for proximity search, and (2) more optimistic generalization bounds.
Efficient Classification for Metric Data
Jul 10, 2014

Recent advances in large-margin classification of data residing in general metric spaces (rather than Hilbert spaces) enable classification under various natural metrics, such as string edit and earthmover distance. A general framework developed for this purpose by von Luxburg and Bousquet [JMLR, 2004] left open the questions of computational efficiency and of providing direct bounds on generalization error. We design a new algorithm for classification in general metric spaces, whose runtime and accuracy depend on the doubling dimension of the data points, and can thus achieve superior classification performance in many common scenarios. The algorithmic core of our approach is an approximate (rather than exact) solution to the classical problems of Lipschitz extension and of Nearest Neighbor Search. The algorithm's generalization performance is guaranteed via the fat-shattering dimension of Lipschitz classifiers, and we present experimental evidence of its superiority to some common kernel methods. As a by-product, we offer a new perspective on the nearest neighbor classifier, which yields significantly sharper risk asymptotics than the classic analysis of Cover and Hart [IEEE Trans. Info. Theory, 1967].