 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA model for full local image interpretation
Oct 17, 2021



We describe a computational model of humans' ability to provide a detailed interpretation of components in a scene. Humans can identify in an image meaningful components almost everywhere, and identifying these components is an essential part of the visual process, and of understanding the surrounding scene and its potential meaning to the viewer. Detailed interpretation is beyond the scope of current models of visual recognition. Our model suggests that this is a fundamental limitation, related to the fact that existing models rely on feed-forward but limited top-down processing. In our model, a first recognition stage leads to the initial activation of class candidates, which is incomplete and with limited accuracy. This stage then triggers the application of class-specific interpretation and validation processes, which recover richer and more accurate interpretation of the visible scene. We discuss implications of the model for visual interpretation by humans and by computer vision models.
* Published in the Proceedings of the 37th Annual Meeting of the Cognitive Science Society (CogSci), 2015
Image interpretation by iterative bottom-up top-down processing
May 12, 2021

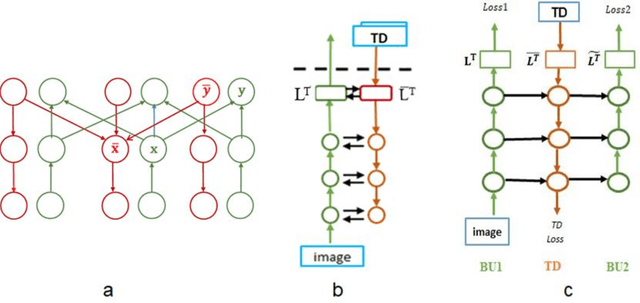
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
Structured learning and detailed interpretation of minimal object images
Nov 29, 2017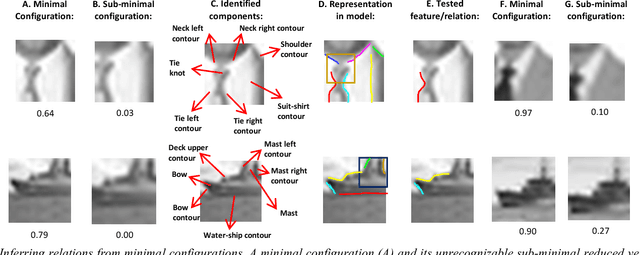
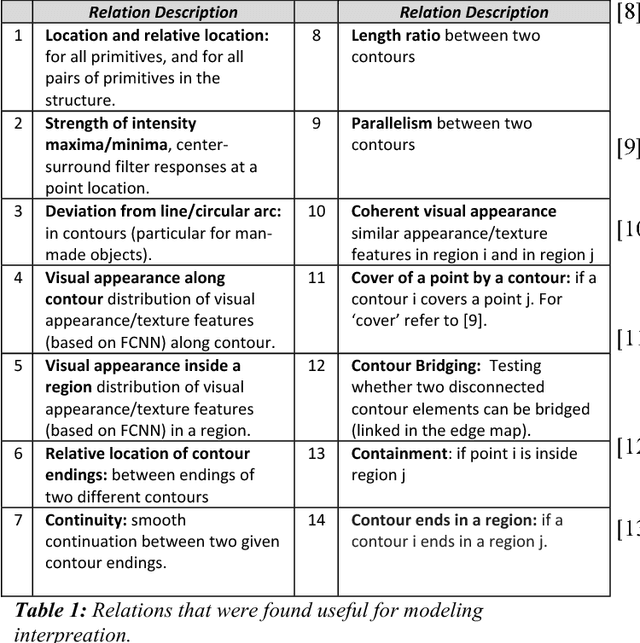


We model the process of human full interpretation of object images, namely the ability to identify and localize all semantic features and parts that are recognized by human observers. The task is approached by dividing the interpretation of the complete object to the interpretation of multiple reduced but interpretable local regions. We model interpretation by a structured learning framework, in which there are primitive components and relations that play a useful role in local interpretation by humans. To identify useful components and relations used in the interpretation process, we consider the interpretation of minimal configurations, namely reduced local regions that are minimal in the sense that further reduction will turn them unrecognizable and uninterpretable. We show experimental results of our model, and results of predicting and testing relations that were useful to the model via transformed minimal images.