 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured learning and detailed interpretation of minimal object images
Paper and Code
Nov 29, 2017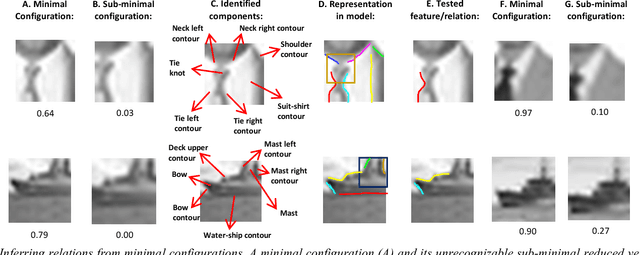
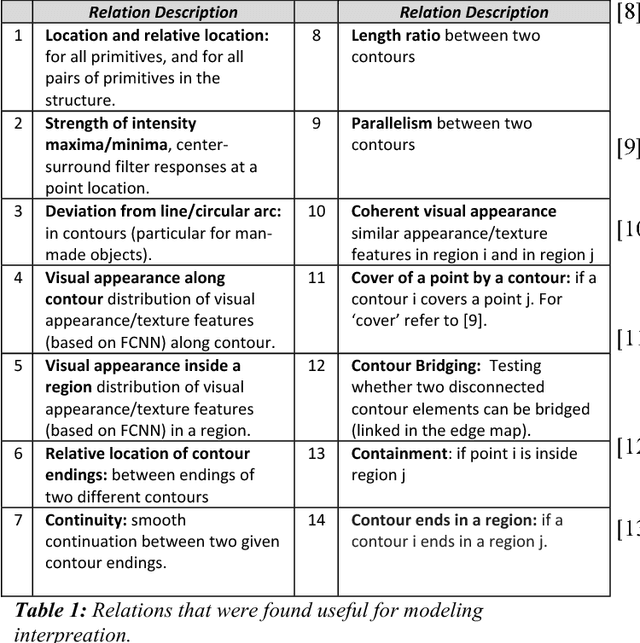


We model the process of human full interpretation of object images, namely the ability to identify and localize all semantic features and parts that are recognized by human observers. The task is approached by dividing the interpretation of the complete object to the interpretation of multiple reduced but interpretable local regions. We model interpretation by a structured learning framework, in which there are primitive components and relations that play a useful role in local interpretation by humans. To identify useful components and relations used in the interpretation process, we consider the interpretation of minimal configurations, namely reduced local regions that are minimal in the sense that further reduction will turn them unrecognizable and uninterpretable. We show experimental results of our model, and results of predicting and testing relations that were useful to the model via transformed minimal images.