 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Level Perceptual Similarity is Enabled by Learning Diverse Tasks
Paper and Code
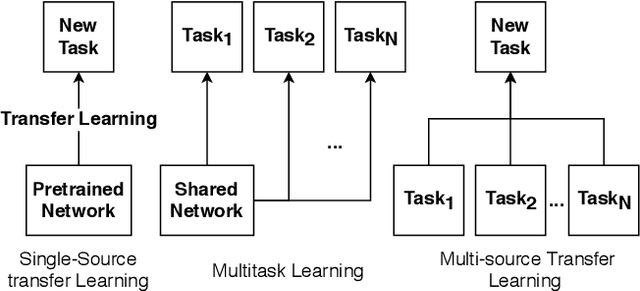
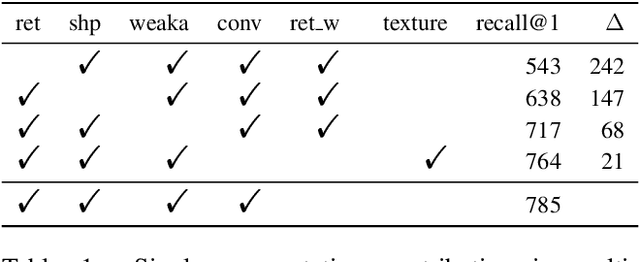
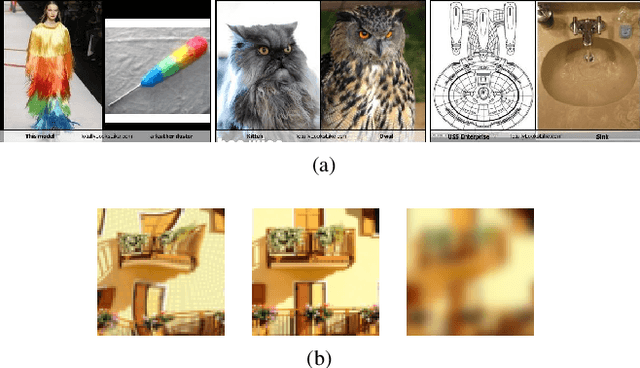

Predicting human perceptual similarity is a challenging subject of ongoing research. The visual process underlying this aspect of human vision is thought to employ multiple different levels of visual analysis (shapes, objects, texture, layout, color, etc). In this paper, we postulate that the perception of image similarity is not an explicitly learned capability, but rather one that is a byproduct of learning others. This claim is supported by leveraging representations learned from a diverse set of visual tasks and using them jointly to predict perceptual similarity. This is done via simple feature concatenation, without any further learning. Nevertheless, experiments performed on the challenging Totally-Looks-Like (TLL) benchmark significantly surpass recent baselines, closing much of the reported gap towards prediction of human perceptual similarity. We provide an analysis of these results and discuss them in a broader context of emergent visual capabilities and their implications on the course of machine-vision research.