 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging Images For Minds and Machines
Paper and Code
Feb 13, 2018
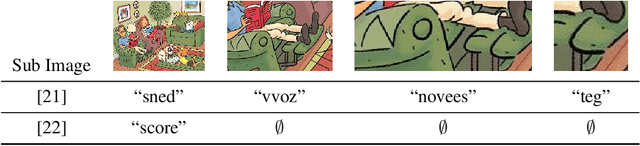
There is no denying the tremendous leap in the performance of machine learning methods in the past half-decade. Some might even say that specific sub-fields in pattern recognition, such as machine-vision, are as good as solved, reaching human and super-human levels. Arguably, lack of training data and computation power are all that stand between us and solving the remaining ones. In this position paper we underline cases in vision which are challenging to machines and even to human observers. This is to show limitations of contemporary models that are hard to ameliorate by following the current trend to increase training data, network capacity or computational power. Moreover, we claim that attempting to do so is in principle a suboptimal approach. We provide a taster of such examples in hope to encourage and challenge the machine learning community to develop new directions to solve the said difficulties.