 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
Physical Adversarial Attack on Monocular Depth Estimation via Shape-Varying Patches
Jul 24, 2024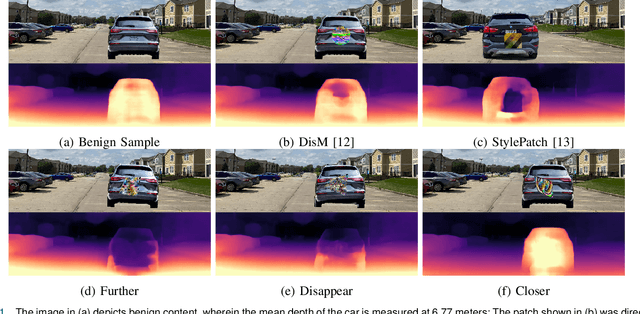
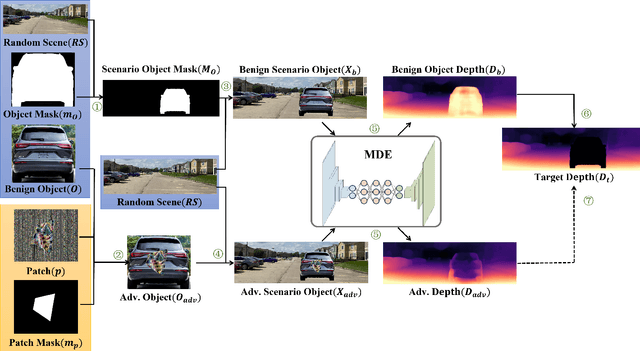
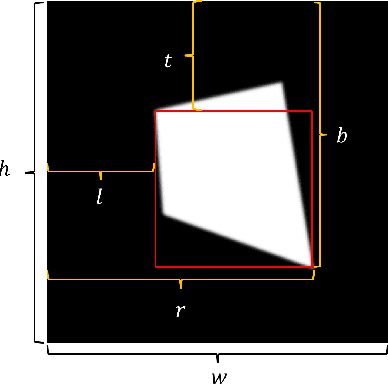

Adversarial attacks against monocular depth estimation (MDE) systems pose significant challenges, particularly in safety-critical applications such as autonomous driving. Existing patch-based adversarial attacks for MDE are confined to the vicinity of the patch, making it difficult to affect the entire target. To address this limitation, we propose a physics-based adversarial attack on monocular depth estimation, employing a framework called Attack with Shape-Varying Patches (ASP), aiming to optimize patch content, shape, and position to maximize effectiveness. We introduce various mask shapes, including quadrilateral, rectangular, and circular masks, to enhance the flexibility and efficiency of the attack. Furthermore, we propose a new loss function to extend the influence of the patch beyond the overlapping regions. Experimental results demonstrate that our attack method generates an average depth error of 18 meters on the target car with a patch area of 1/9, affecting over 98\% of the target area.
Supervised Homogeneity Fusion: a Combinatorial Approach
Jan 04, 2022
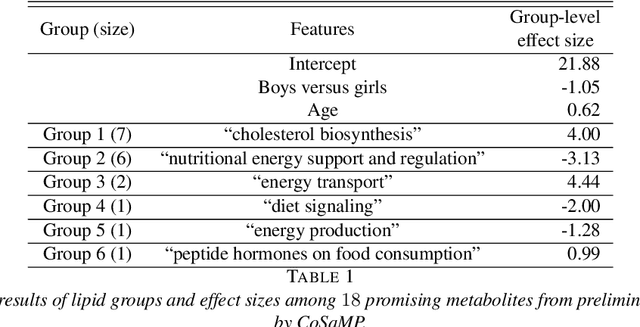
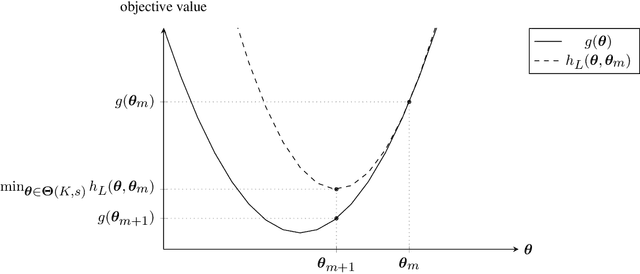
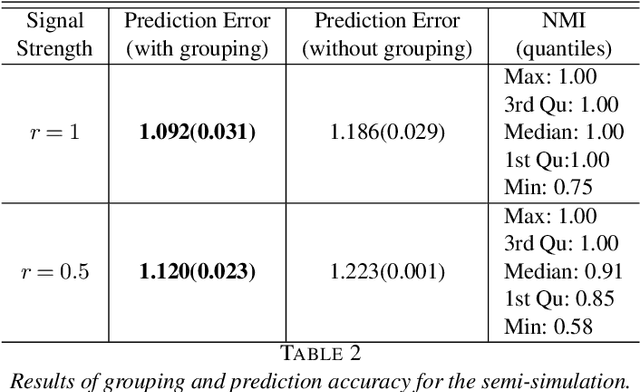
Fusing regression coefficients into homogenous groups can unveil those coefficients that share a common value within each group. Such groupwise homogeneity reduces the intrinsic dimension of the parameter space and unleashes sharper statistical accuracy. We propose and investigate a new combinatorial grouping approach called $L_0$-Fusion that is amenable to mixed integer optimization (MIO). On the statistical aspect, we identify a fundamental quantity called grouping sensitivity that underpins the difficulty of recovering the true groups. We show that $L_0$-Fusion achieves grouping consistency under the weakest possible requirement of the grouping sensitivity: if this requirement is violated, then the minimax risk of group misspecification will fail to converge to zero. Moreover, we show that in the high-dimensional regime, one can apply $L_0$-Fusion coupled with a sure screening set of features without any essential loss of statistical efficiency, while reducing the computational cost substantially. On the algorithmic aspect, we provide a MIO formulation for $L_0$-Fusion along with a warm start strategy. Simulation and real data analysis demonstrate that $L_0$-Fusion exhibits superiority over its competitors in terms of grouping accuracy.
Iso-Points: Optimizing Neural Implicit Surfaces with Hybrid Representations
Dec 11, 2020



Neural implicit functions have emerged as a powerful representation for surfaces in 3D. Such a function can encode a high quality surface with intricate details into the parameters of a deep neural network. However, optimizing for the parameters for accurate and robust reconstructions remains a challenge, especially when the input data is noisy or incomplete. In this work, we develop a hybrid neural surface representation that allows us to impose geometry-aware sampling and regularization, which significantly improves the fidelity of reconstructions. We propose to use \emph{iso-points} as an explicit representation for a neural implicit function. These points are computed and updated on-the-fly during training to capture important geometric features and impose geometric constraints on the optimization. We demonstrate that our method can be adopted to improve state-of-the-art techniques for reconstructing neural implicit surfaces from multi-view images or point clouds. Quantitative and qualitative evaluations show that, compared with existing sampling and optimization methods, our approach allows faster convergence, better generalization, and accurate recovery of details and topology.
Differentiable Surface Splatting for Point-based Geometry Processing
Jun 14, 2019



We propose Differentiable Surface Splatting (DSS), a high-fidelity differentiable renderer for point clouds. Gradients for point locations and normals are carefully designed to handle discontinuities of the rendering function. Regularization terms are introduced to ensure uniform distribution of the points on the underlying surface. We demonstrate applications of DSS to inverse rendering for geometry synthesis and denoising, where large scale topological changes, as well as small scale detail modifications, are accurately and robustly handled without requiring explicit connectivity, outperforming state-of-the-art techniques. The data and code are at https://github.com/yifita/DSS.
Patch-based Progressive 3D Point Set Upsampling
Nov 29, 2018

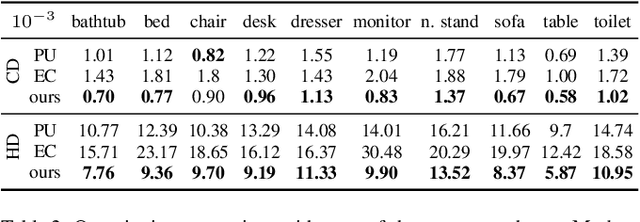

We present a detail-driven deep neural network for point set upsampling. A high-resolution point set is essential for point-based rendering and surface reconstruction. Inspired by the recent success of neural image super-resolution techniques, we progressively train a cascade of patch-based upsampling networks on different levels of detail end-to-end. We propose a series of architectural design contributions that lead to a substantial performance boost. The effect of each technical contribution is demonstrated in an ablation study. Qualitative and quantitative experiments show that our method significantly outperforms the state-of-the-art learning-based and optimazation-based approaches, both in terms of handling low-resolution inputs and revealing high-fidelity details.
Specular-to-Diffuse Translation for Multi-View Reconstruction
Jul 30, 2018



Most multi-view 3D reconstruction algorithms, especially when shape-from-shading cues are used, assume that object appearance is predominantly diffuse. To alleviate this restriction, we introduce S2Dnet, a generative adversarial network for transferring multiple views of objects with specular reflection into diffuse ones, so that multi-view reconstruction methods can be applied more effectively. Our network extends unsupervised image-to-image translation to multi-view "specular to diffuse" translation. To preserve object appearance across multiple views, we introduce a Multi-View Coherence loss (MVC) that evaluates the similarity and faithfulness of local patches after the view-transformation. Our MVC loss ensures that the similarity of local correspondences among multi-view images is preserved under the image-to-image translation. As a result, our network yields significantly better results than several single-view baseline techniques. In addition, we carefully design and generate a large synthetic training data set using physically-based rendering. During testing, our network takes only the raw glossy images as input, without extra information such as segmentation masks or lighting estimation. Results demonstrate that multi-view reconstruction can be significantly improved using the images filtered by our network. We also show promising performance on real world training and testing data.