 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiCU: End-to-End Smart Home Command Understanding with Large Language Model
May 31, 2026Command understanding systems in smart home ecosystems can automate device control and substantially improve user experience. However, while they perform well on precise utterances (e.g., "turn on the bedroom light"), they struggle with ambiguous or misaligned commands (e.g., "make the bedroom cozy"). Large language models (LLMs) generalize well across various domains and can outperform traditional rule-based systems on such tasks, but their effectiveness is often constrained by scarce domain-specific data, insufficient task-specific adaptation, and high computational costs. In this paper, we propose an automated training data synthesis workflow using user logs and LLMs; then we build MiCU, a domain-specific LLM that excels at command understanding. Specifically, we employ curriculum learning to inject domain knowledge into the base LLM, then we enhance its reasoning ability via cold-start training combined with reinforcement learning (RL) guided by domain-specific thinking rules. Additionally, we introduce a token compression technique that condenses device description into a single special token, substantially reducing inference overhead and enabling \model-fast, an efficient variant optimized for long inputs. Extensive experiments show that MiCU significantly outperforms baselines, with an average accuracy gain of 20.01% across all device categories. We have deployed MiCU in the Xiaomi Home app, receiving approximately 1.7 million page views per day. Production evaluations show that MiCU reduces user correction rate by 1.57% and increases human audited accuracy by 32.05%. Our data and code are available at https://github.com/xiaomi-research/iot_spec_llm
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.
Step1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
DynaSurfGS: Dynamic Surface Reconstruction with Planar-based Gaussian Splatting
Aug 26, 2024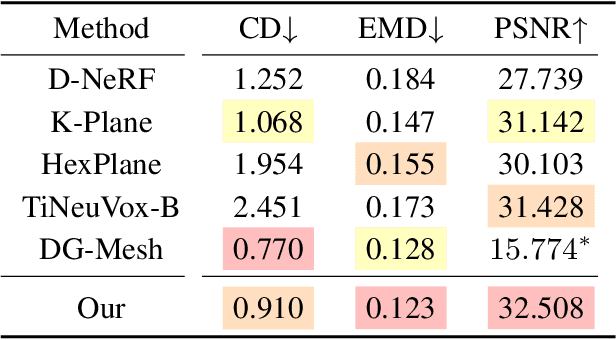
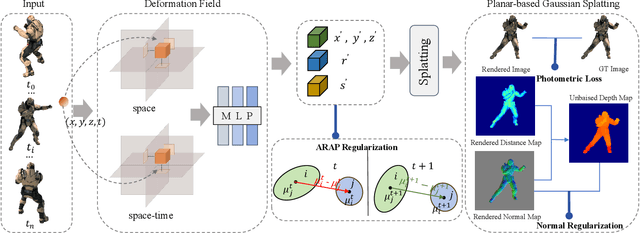
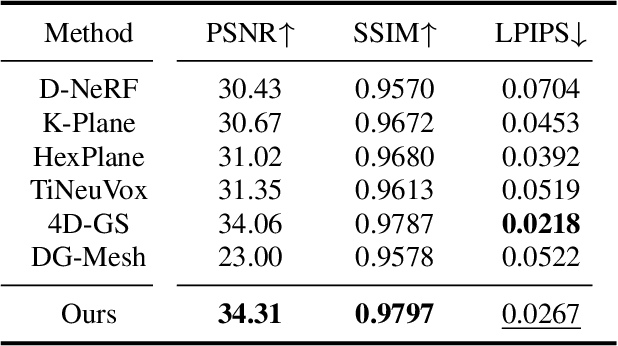

Dynamic scene reconstruction has garnered significant attention in recent years due to its capabilities in high-quality and real-time rendering. Among various methodologies, constructing a 4D spatial-temporal representation, such as 4D-GS, has gained popularity for its high-quality rendered images. However, these methods often produce suboptimal surfaces, as the discrete 3D Gaussian point clouds fail to align with the object's surface precisely. To address this problem, we propose DynaSurfGS to achieve both photorealistic rendering and high-fidelity surface reconstruction of dynamic scenarios. Specifically, the DynaSurfGS framework first incorporates Gaussian features from 4D neural voxels with the planar-based Gaussian Splatting to facilitate precise surface reconstruction. It leverages normal regularization to enforce the smoothness of the surface of dynamic objects. It also incorporates the as-rigid-as-possible (ARAP) constraint to maintain the approximate rigidity of local neighborhoods of 3D Gaussians between timesteps and ensure that adjacent 3D Gaussians remain closely aligned throughout. Extensive experiments demonstrate that DynaSurfGS surpasses state-of-the-art methods in both high-fidelity surface reconstruction and photorealistic rendering.
GraftNet: An Engineering Implementation of CNN for Fine-grained Multi-label Task
Apr 27, 2020
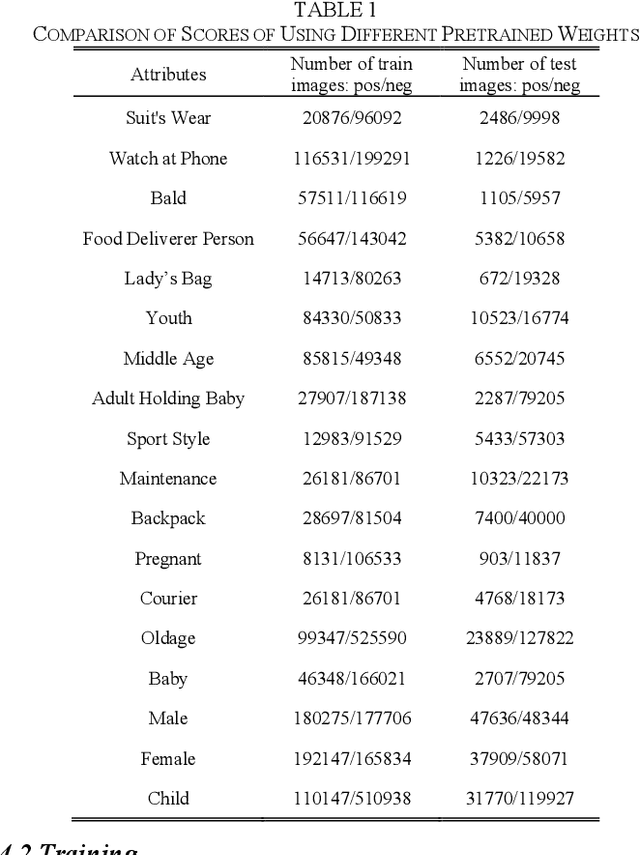
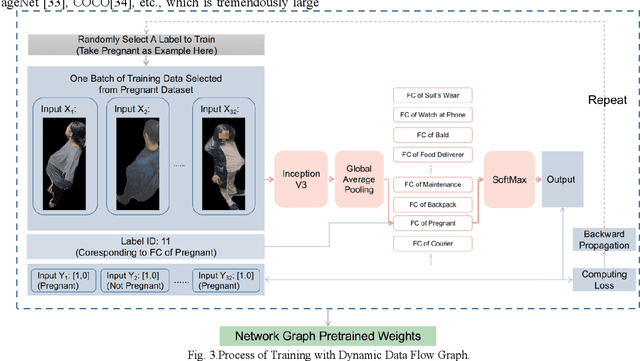

Multi-label networks with branches are proved to perform well in both accuracy and speed, but lacks flexibility in providing dynamic extension onto new labels due to the low efficiency of re-work on annotating and training. For multi-label classification task, to cover new labels we need to annotate not only newly collected images, but also the previous whole dataset to check presence of these new labels. Also training on whole re-annotated dataset costs much time. In order to recognize new labels more effectively and accurately, we propose GraftNet, which is a customizable tree-like network with its trunk pretrained with a dynamic graph for generic feature extraction, and branches separately trained on sub-datasets with single label to improve accuracy. GraftNet could reduce cost, increase flexibility, and incrementally handle new labels. Experimental results show that it has good performance on our human attributes recognition task, which is fine-grained multi-label classification.
Diversity-Generated Image Inpainting with Style Extraction
Dec 04, 2019



The latest methods based on deep learning have achieved amazing results regarding the complex work of inpainting large missing areas in an image. This type of method generally attempts to generate one single "optimal" inpainting result, ignoring many other plausible results. However, considering the uncertainty of the inpainting task, one sole result can hardly be regarded as a desired regeneration of the missing area. In view of this weakness, which is related to the design of the previous algorithms, we propose a novel deep generative model equipped with a brand new style extractor which can extract the style noise (a latent vector) from the ground truth image. Once obtained, the extracted style noise and the ground truth image are both input into the generator. We also craft a consistency loss that guides the generated image to approximate the ground truth. Meanwhile, the same extractor captures the style noise from the generated image, which is forced to approach the input noise according to the consistency loss. After iterations, our generator is able to learn the styles corresponding to multiple sets of noise. The proposed model can generate a (sufficiently large) number of inpainting results consistent with the context semantics of the image. Moreover, we check the effectiveness of our model on three databases, i.e., CelebA, Agricultural Disease, and MauFlex. Compared to state-of-the-art inpainting methods, this model is able to offer desirable inpainting results with both a better quality and higher diversity, for example, on the human face, we can even output the different gaze angles of the eyes and whether they have glasses, etc. The code and model will be made available on https://github.com/vivitsai/SEGAN.