 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Human Feedback for Text-to-Image Generation
Dec 15, 2023
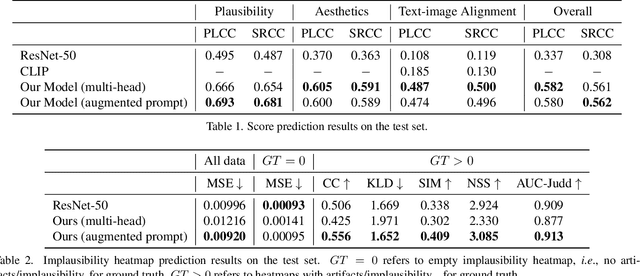
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
GazeGAN - Unpaired Adversarial Image Generation for Gaze Estimation
Nov 27, 2017
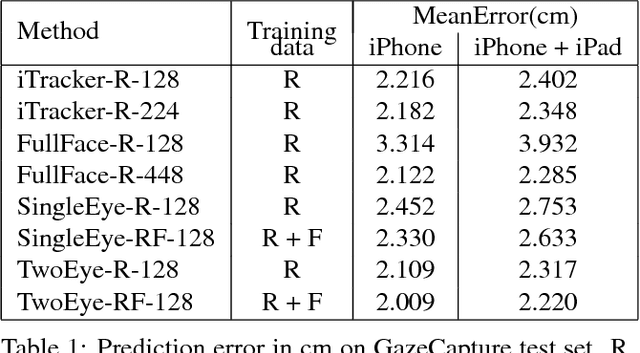

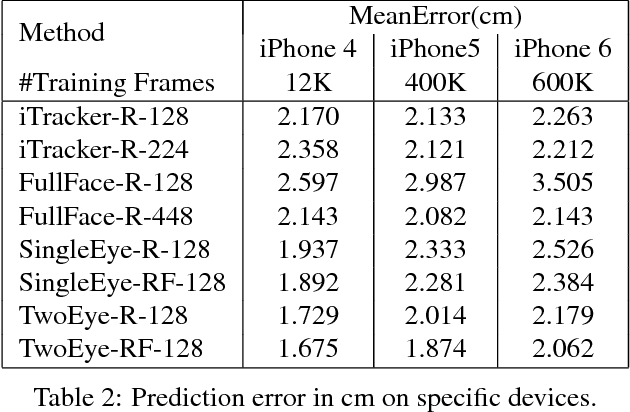
Recent research has demonstrated the ability to estimate gaze on mobile devices by performing inference on the image from the phone's front-facing camera, and without requiring specialized hardware. While this offers wide potential applications such as in human-computer interaction, medical diagnosis and accessibility (e.g., hands free gaze as input for patients with motor disorders), current methods are limited as they rely on collecting data from real users, which is a tedious and expensive process that is hard to scale across devices. There have been some attempts to synthesize eye region data using 3D models that can simulate various head poses and camera settings, however these lack in realism. In this paper, we improve upon a recently suggested method, and propose a generative adversarial framework to generate a large dataset of high resolution colorful images with high diversity (e.g., in subjects, head pose, camera settings) and realism, while simultaneously preserving the accuracy of gaze labels. The proposed approach operates on extended regions of the eye, and even completes missing parts of the image. Using this rich synthesized dataset, and without using any additional training data from real users, we demonstrate improvements over state-of-the-art for estimating 2D gaze position on mobile devices. We further demonstrate cross-device generalization of model performance, as well as improved robustness to diverse head pose, blur and distance.