 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectralViTs: General Hyperspectral Models for On-board Remote Sensing
Paper and Code
Oct 24, 2024


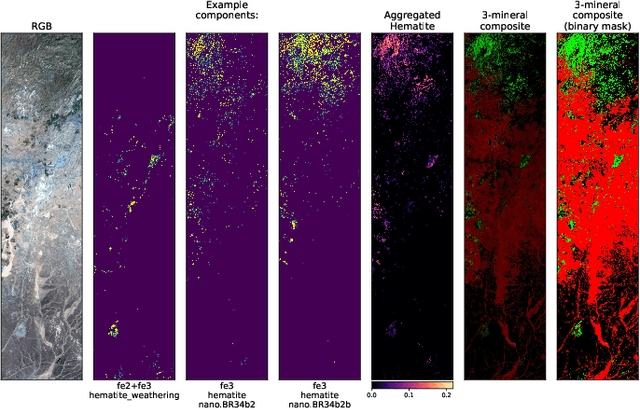
On-board processing of hyperspectral data with machine learning models would enable unprecedented amount of autonomy for a wide range of tasks, for example methane detection or mineral identification. This can enable early warning system and could allow new capabilities such as automated scheduling across constellations of satellites. Classical methods suffer from high false positive rates and previous deep learning models exhibit prohibitive computational requirements. We propose fast and accurate machine learning architectures which support end-to-end training with data of high spectral dimension without relying on hand-crafted products or spectral band compression preprocessing. We evaluate our models on two tasks related to hyperspectral data processing. With our proposed general architectures, we improve the F1 score of the previous methane detection state-of-the-art models by 27% on a newly created synthetic dataset and by 13% on the previously released large benchmark dataset. We also demonstrate that training models on the synthetic dataset improves performance of models finetuned on the dataset of real events by 6.9% in F1 score in contrast with training from scratch. On a newly created dataset for mineral identification, our models provide 3.5% improvement in the F1 score in contrast to the default versions of the models. With our proposed models we improve the inference speed by 85% in contrast to previous classical and deep learning approaches by removing the dependency on classically computed features. With our architecture, one capture from the EMIT sensor can be processed within 30 seconds on realistic proxy of the ION-SCV 004 satellite.