 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Inversion for Property-Targeted Materials Design: Application to Shape Memory Alloys
Aug 11, 2025The design of shape memory alloys (SMAs) with high transformation temperatures and large mechanical work output remains a longstanding challenge in functional materials engineering. Here, we introduce a data-driven framework based on generative adversarial network (GAN) inversion for the inverse design of high-performance SMAs. By coupling a pretrained GAN with a property prediction model, we perform gradient-based latent space optimization to directly generate candidate alloy compositions and processing parameters that satisfy user-defined property targets. The framework is experimentally validated through the synthesis and characterization of five NiTi-based SMAs. Among them, the Ni$_{49.8}$Ti$_{26.4}$Hf$_{18.6}$Zr$_{5.2}$ alloy achieves a high transformation temperature of 404 $^\circ$C, a large mechanical work output of 9.9 J/cm$^3$, a transformation enthalpy of 43 J/g , and a thermal hysteresis of 29 {\deg}C, outperforming existing NiTi alloys. The enhanced performance is attributed to a pronounced transformation volume change and a finely dispersed of Ti$_2$Ni-type precipitates, enabled by sluggish Zr and Hf diffusion, and semi-coherent interfaces with localized strain fields. This study demonstrates that GAN inversion offers an efficient and generalizable route for the property-targeted discovery of complex alloys.
Universal Semantic Embeddings of Chemical Elements for Enhanced Materials Inference and Discovery
Feb 19, 2025We present a framework for generating universal semantic embeddings of chemical elements to advance materials inference and discovery. This framework leverages ElementBERT, a domain-specific BERT-based natural language processing model trained on 1.29 million abstracts of alloy-related scientific papers, to capture latent knowledge and contextual relationships specific to alloys. These semantic embeddings serve as robust elemental descriptors, consistently outperforming traditional empirical descriptors with significant improvements across multiple downstream tasks. These include predicting mechanical and transformation properties, classifying phase structures, and optimizing materials properties via Bayesian optimization. Applications to titanium alloys, high-entropy alloys, and shape memory alloys demonstrate up to 23% gains in prediction accuracy. Our results show that ElementBERT surpasses general-purpose BERT variants by encoding specialized alloy knowledge. By bridging contextual insights from scientific literature with quantitative inference, our framework accelerates the discovery and optimization of advanced materials, with potential applications extending beyond alloys to other material classes.
Differentiable architecture search with multi-dimensional attention for spiking neural networks
Nov 01, 2024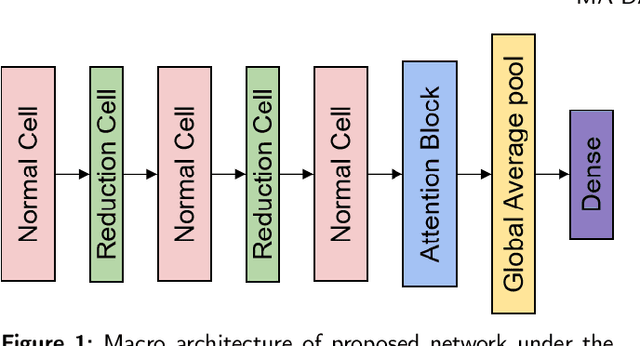
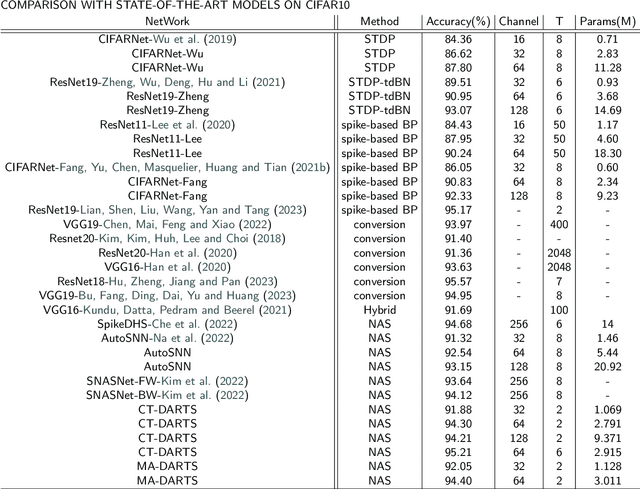
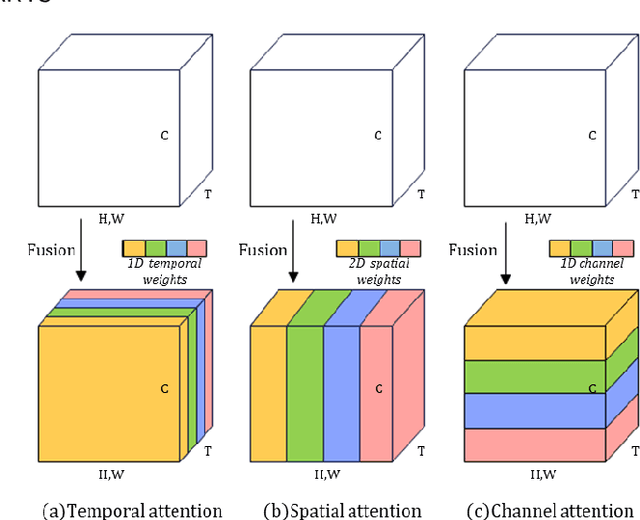
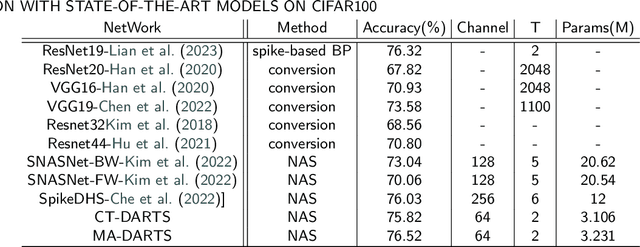
Spiking Neural Networks (SNNs) have gained enormous popularity in the field of artificial intelligence due to their low power consumption. However, the majority of SNN methods directly inherit the structure of Artificial Neural Networks (ANN), usually leading to sub-optimal model performance in SNNs. To alleviate this problem, we integrate Neural Architecture Search (NAS) method and propose Multi-Attention Differentiable Architecture Search (MA-DARTS) to directly automate the search for the optimal network structure of SNNs. Initially, we defined a differentiable two-level search space and conducted experiments within micro architecture under a fixed layer. Then, we incorporated a multi-dimensional attention mechanism and implemented the MA-DARTS algorithm in this search space. Comprehensive experiments demonstrate our model achieves state-of-the-art performance on classification compared to other methods under the same parameters with 94.40% accuracy on CIFAR10 dataset and 76.52% accuracy on CIFAR100 dataset. Additionally, we monitored and assessed the number of spikes (NoS) in each cell during the whole experiment. Notably, the number of spikes of the whole model stabilized at approximately 110K in validation and 100k in training on datasets.