 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Training Wheels: Speeding up Training with a Simple Controller for Deep Reinforcement Learning
Paper and Code
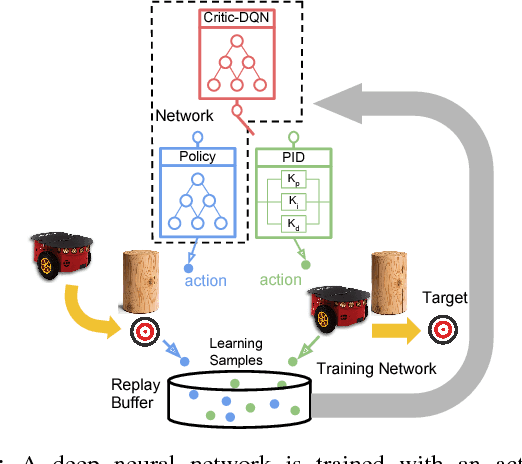
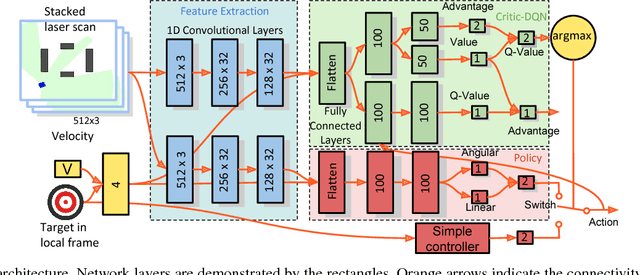
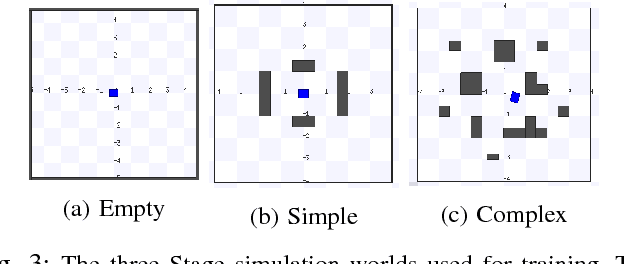
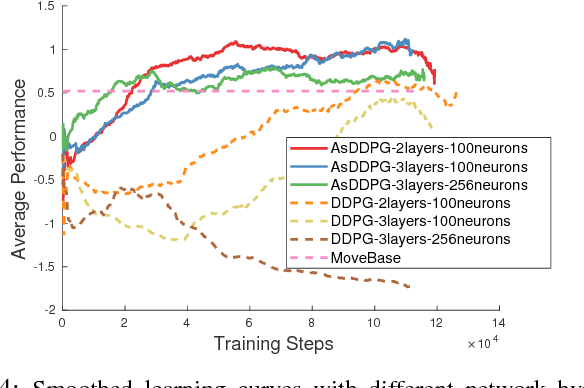
Deep Reinforcement Learning (DRL) has been applied successfully to many robotic applications. However, the large number of trials needed for training is a key issue. Most of existing techniques developed to improve training efficiency (e.g. imitation) target on general tasks rather than being tailored for robot applications, which have their specific context to benefit from. We propose a novel framework, Assisted Reinforcement Learning, where a classical controller (e.g. a PID controller) is used as an alternative, switchable policy to speed up training of DRL for local planning and navigation problems. The core idea is that the simple control law allows the robot to rapidly learn sensible primitives, like driving in a straight line, instead of random exploration. As the actor network becomes more advanced, it can then take over to perform more complex actions, like obstacle avoidance. Eventually, the simple controller can be discarded entirely. We show that not only does this technique train faster, it also is less sensitive to the structure of the DRL network and consistently outperforms a standard Deep Deterministic Policy Gradient network. We demonstrate the results in both simulation and real-world experiments.