 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
GLISP: A Scalable GNN Learning System by Exploiting Inherent Structural Properties of Graphs
Jan 06, 2024As a powerful tool for modeling graph data, Graph Neural Networks (GNNs) have received increasing attention in both academia and industry. Nevertheless, it is notoriously difficult to deploy GNNs on industrial scale graphs, due to their huge data size and complex topological structures. In this paper, we propose GLISP, a sampling based GNN learning system for industrial scale graphs. By exploiting the inherent structural properties of graphs, such as power law distribution and data locality, GLISP addresses the scalability and performance issues that arise at different stages of the graph learning process. GLISP consists of three core components: graph partitioner, graph sampling service and graph inference engine. The graph partitioner adopts the proposed vertex-cut graph partitioning algorithm AdaDNE to produce balanced partitioning for power law graphs, which is essential for sampling based GNN systems. The graph sampling service employs a load balancing design that allows the one hop sampling request of high degree vertices to be handled by multiple servers. In conjunction with the memory efficient data structure, the efficiency and scalability are effectively improved. The graph inference engine splits the $K$-layer GNN into $K$ slices and caches the vertex embeddings produced by each slice in the data locality aware hybrid caching system for reuse, thus completely eliminating redundant computation caused by the data dependency of graph. Extensive experiments show that GLISP achieves up to $6.53\times$ and $70.77\times$ speedups over existing GNN systems for training and inference tasks, respectively, and can scale to the graph with over 10 billion vertices and 40 billion edges with limited resources.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
Augmenting Anchors by the Detector Itself
May 28, 2021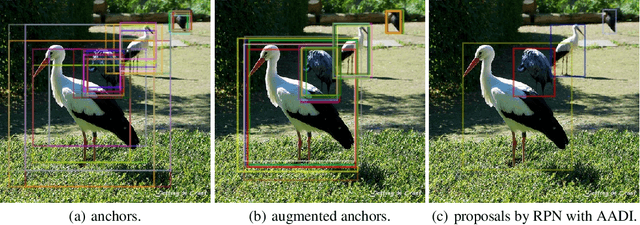
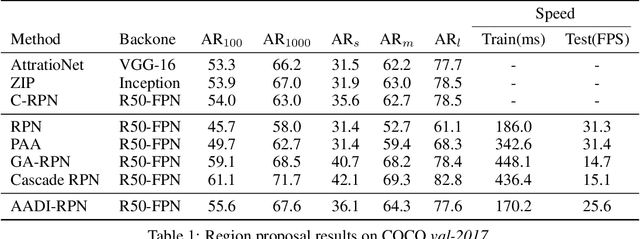

It is difficult to determine the scale and aspect ratio of anchors for anchor-based object detection methods. Current state-of-the-art object detectors either determine anchor parameters according to objects' shape and scale in a dataset, or avoid this problem by utilizing anchor-free method. In this paper, we propose a gradient-free anchor augmentation method named AADI, which means Augmenting Anchors by the Detector Itself. AADI is not an anchor-free method, but it converts the scale and aspect ratio of anchors from a continuous space to a discrete space, which greatly alleviates the problem of anchors' designation. Furthermore, AADI does not add any parameters or hyper-parameters, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that AADI has obvious advantages for both two-stage and single-stage methods, specifically, AADI achieves at least 2.1 AP improvements on Faster R-CNN and 1.6 AP improvements on RetinaNet, using ResNet-50 model. We hope that this simple and cost-efficient method can be widely used in object detection.
Augmenting Proposals by the Detector Itself
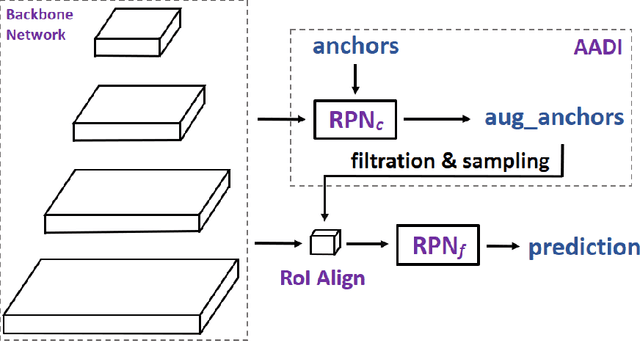
Jan 28, 2021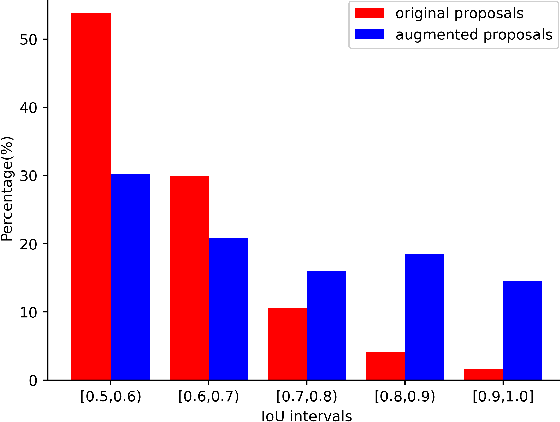
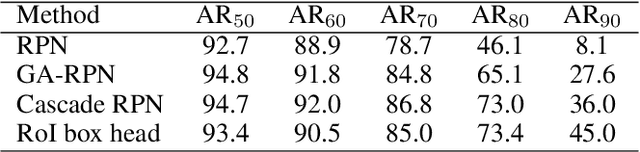
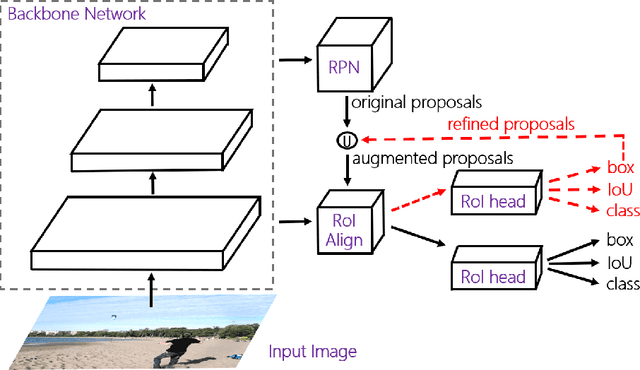
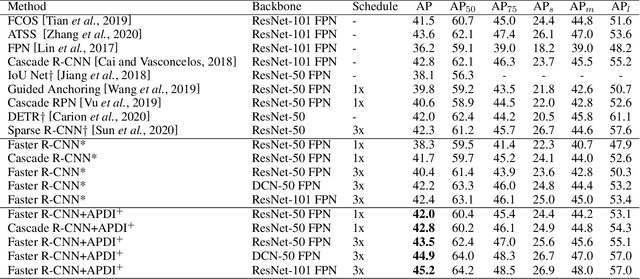
Lacking enough high quality proposals for RoI box head has impeded two-stage and multi-stage object detectors for a long time, and many previous works try to solve it via improving RPN's performance or manually generating proposals from ground truth. However, these methods either need huge training and inference costs or bring little improvements. In this paper, we design a novel training method named APDI, which means augmenting proposals by the detector itself and can generate proposals with higher quality. Furthermore, APDI makes it possible to integrate IoU head into RoI box head. And it does not add any hyperparameter, which is beneficial for future research and downstream tasks. Extensive experiments on COCO dataset show that our method brings at least 2.7 AP improvements on Faster R-CNN with various backbones, and APDI can cooperate with advanced RPNs, such as GA-RPN and Cascade RPN, to obtain extra gains. Furthermore, it brings significant improvements on Cascade R-CNN.