 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Prompted Artist Names from Generated Images
Jul 24, 2025A common and controversial use of text-to-image models is to generate pictures by explicitly naming artists, such as "in the style of Greg Rutkowski". We introduce a benchmark for prompted-artist recognition: predicting which artist names were invoked in the prompt from the image alone. The dataset contains 1.95M images covering 110 artists and spans four generalization settings: held-out artists, increasing prompt complexity, multiple-artist prompts, and different text-to-image models. We evaluate feature similarity baselines, contrastive style descriptors, data attribution methods, supervised classifiers, and few-shot prototypical networks. Generalization patterns vary: supervised and few-shot models excel on seen artists and complex prompts, whereas style descriptors transfer better when the artist's style is pronounced; multi-artist prompts remain the most challenging. Our benchmark reveals substantial headroom and provides a public testbed to advance the responsible moderation of text-to-image models. We release the dataset and benchmark to foster further research: https://graceduansu.github.io/IdentifyingPromptedArtists/
Customizing Text-to-Image Diffusion with Camera Viewpoint Control
Apr 18, 2024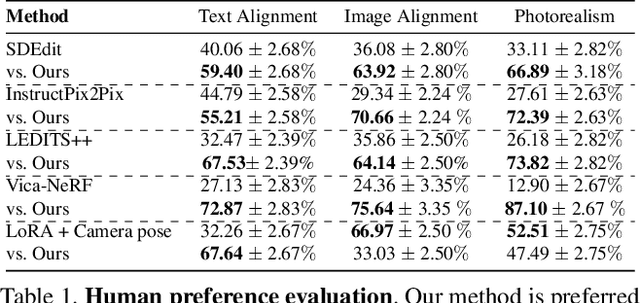


Model customization introduces new concepts to existing text-to-image models, enabling the generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding "top-view") to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of camera viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the object's appearance and geometry while reducing overfitting to the input multi-view images. Our method outperforms existing image editing and model personalization baselines in preserving the custom object's identity while following the input text prompt and the object's camera pose.
DeepScribe: Localization and Classification of Elamite Cuneiform Signs Via Deep Learning
Jun 02, 2023



Twenty-five hundred years ago, the paperwork of the Achaemenid Empire was recorded on clay tablets. In 1933, archaeologists from the University of Chicago's Oriental Institute (OI) found tens of thousands of these tablets and fragments during the excavation of Persepolis. Many of these tablets have been painstakingly photographed and annotated by expert cuneiformists, and now provide a rich dataset consisting of over 5,000 annotated tablet images and 100,000 cuneiform sign bounding boxes. We leverage this dataset to develop DeepScribe, a modular computer vision pipeline capable of localizing cuneiform signs and providing suggestions for the identity of each sign. We investigate the difficulty of learning subtasks relevant to cuneiform tablet transcription on ground-truth data, finding that a RetinaNet object detector can achieve a localization mAP of 0.78 and a ResNet classifier can achieve a top-5 sign classification accuracy of 0.89. The end-to-end pipeline achieves a top-5 classification accuracy of 0.80. As part of the classification module, DeepScribe groups cuneiform signs into morphological clusters. We consider how this automatic clustering approach differs from the organization of standard, printed sign lists and what we may learn from it. These components, trained individually, are sufficient to produce a system that can analyze photos of cuneiform tablets from the Achaemenid period and provide useful transliteration suggestions to researchers. We evaluate the model's end-to-end performance on locating and classifying signs, providing a roadmap to a linguistically-aware transliteration system, then consider the model's potential utility when applied to other periods of cuneiform writing.