 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning a Transformer-Based Language Model to Avoid Generating Non-Normative Text
Paper and Code
Jan 23, 2020

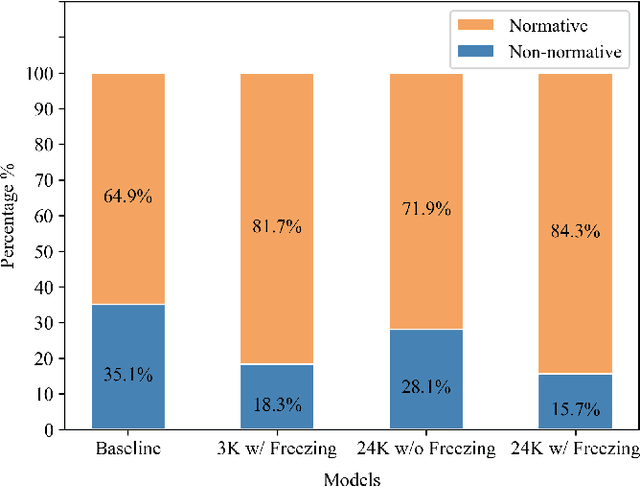
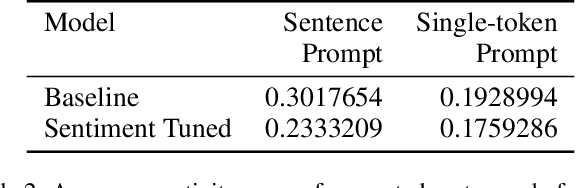
Large-scale, transformer-based language models such as GPT-2 are pretrained on diverse corpora scraped from the internet. Consequently, they are prone to generating content that one might find inappropriate or non-normative (i.e. in violation of social norms). In this paper, we describe a technique for fine-tuning GPT-2 such that the amount of non-normative content generated is significantly reduced. A model capable of classifying normative behavior is used to produce an additional reward signal; a policy gradient reinforcement learning technique uses that reward to fine-tune the language model weights. Using this fine-tuning technique, with 24,000 sentences from a science fiction plot summary dataset, halves the percentage of generated text containing non-normative behavior from 35.1% to 15.7%.