 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-student training improves accuracy and efficiency of machine learning inter-atomic potentials
Paper and Code
Feb 07, 2025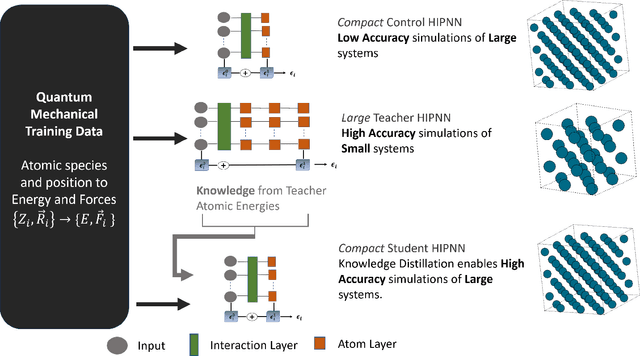

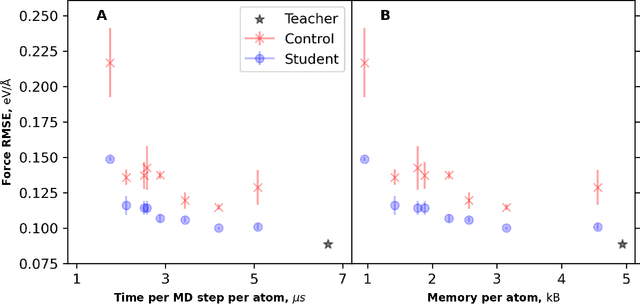
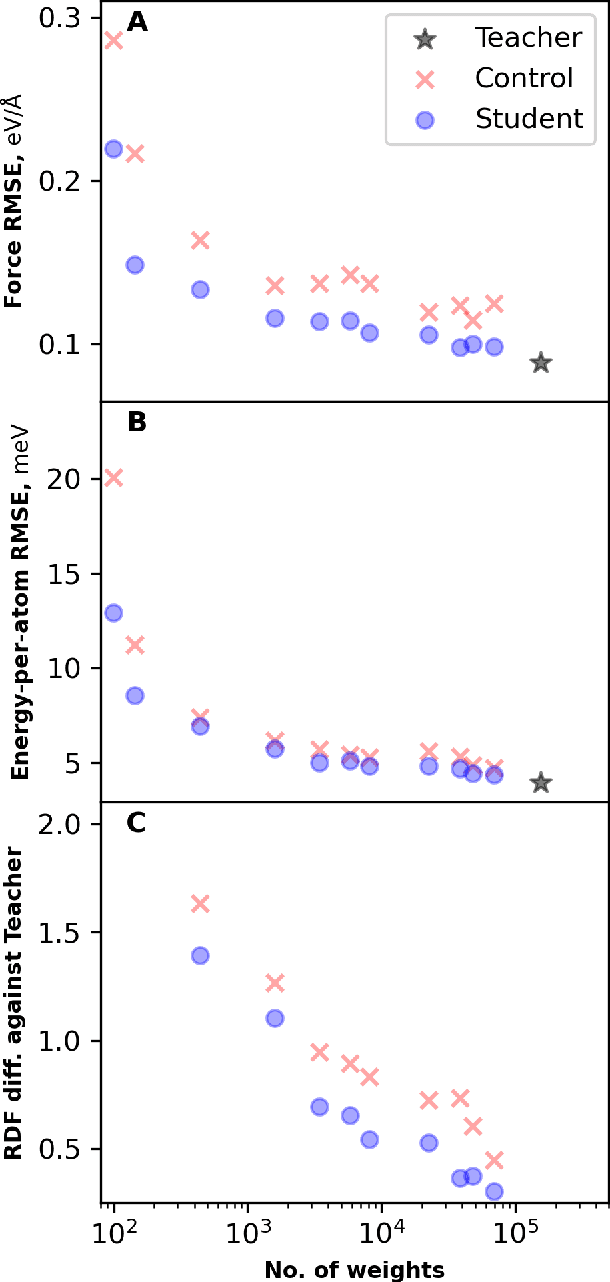
Machine learning inter-atomic potentials (MLIPs) are revolutionizing the field of molecular dynamics (MD) simulations. Recent MLIPs have tended towards more complex architectures trained on larger datasets. The resulting increase in computational and memory costs may prohibit the application of these MLIPs to perform large-scale MD simulations. Here, we present a teacher-student training framework in which the latent knowledge from the teacher (atomic energies) is used to augment the students' training. We show that the light-weight student MLIPs have faster MD speeds at a fraction of the memory footprint compared to the teacher models. Remarkably, the student models can even surpass the accuracy of the teachers, even though both are trained on the same quantum chemistry dataset. Our work highlights a practical method for MLIPs to reduce the resources required for large-scale MD simulations.