 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Acoustic Fields
Apr 01, 2025Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.
Integrating LMM Planners and 3D Skill Policies for Generalizable Manipulation
Jan 30, 2025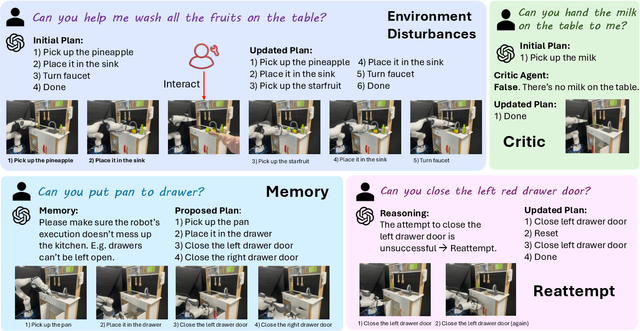
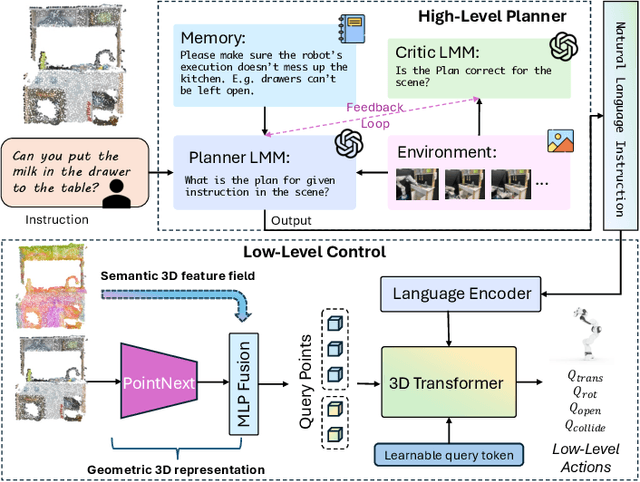

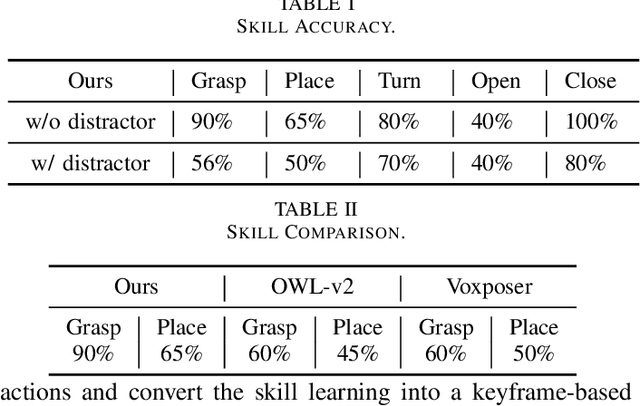
The recent advancements in visual reasoning capabilities of large multimodal models (LMMs) and the semantic enrichment of 3D feature fields have expanded the horizons of robotic capabilities. These developments hold significant potential for bridging the gap between high-level reasoning from LMMs and low-level control policies utilizing 3D feature fields. In this work, we introduce LMM-3DP, a framework that can integrate LMM planners and 3D skill Policies. Our approach consists of three key perspectives: high-level planning, low-level control, and effective integration. For high-level planning, LMM-3DP supports dynamic scene understanding for environment disturbances, a critic agent with self-feedback, history policy memorization, and reattempts after failures. For low-level control, LMM-3DP utilizes a semantic-aware 3D feature field for accurate manipulation. In aligning high-level and low-level control for robot actions, language embeddings representing the high-level policy are jointly attended with the 3D feature field in the 3D transformer for seamless integration. We extensively evaluate our approach across multiple skills and long-horizon tasks in a real-world kitchen environment. Our results show a significant 1.45x success rate increase in low-level control and an approximate 1.5x improvement in high-level planning accuracy compared to LLM-based baselines. Demo videos and an overview of LMM-3DP are available at https://lmm-3dp-release.github.io.
Model-diff: A Tool for Comparative Study of Language Models in the Input Space
Dec 13, 2024



Comparing two (large) language models (LMs) side-by-side and pinpointing their prediction similarities and differences on the same set of inputs are crucial in many real-world scenarios, e.g., one can test if a licensed model was potentially plagiarized by another. Traditional analysis compares the LMs' outputs on some benchmark datasets, which only cover a limited number of inputs of designed perspectives for the intended applications. The benchmark datasets cannot prepare data to cover the test cases from unforeseen perspectives which can help us understand differences between models unbiasedly. In this paper, we propose a new model comparative analysis setting that considers a large input space where brute-force enumeration would be infeasible. The input space can be simply defined as all token sequences that a LM would produce low perplexity on -- we follow this definition in the paper as it would produce the most human-understandable inputs. We propose a novel framework \our that uses text generation by sampling and deweights the histogram of sampling statistics to estimate prediction differences between two LMs in this input space efficiently and unbiasedly. Our method achieves this by drawing and counting the inputs at each prediction difference value in negative log-likelihood. Experiments reveal for the first time the quantitative prediction differences between LMs in a large input space, potentially facilitating the model analysis for applications such as model plagiarism.
Diffusion-based Data Augmentation for Object Counting Problems
Jan 25, 2024Crowd counting is an important problem in computer vision due to its wide range of applications in image understanding. Currently, this problem is typically addressed using deep learning approaches, such as Convolutional Neural Networks (CNNs) and Transformers. However, deep networks are data-driven and are prone to overfitting, especially when the available labeled crowd dataset is limited. To overcome this limitation, we have designed a pipeline that utilizes a diffusion model to generate extensive training data. We are the first to generate images conditioned on a location dot map (a binary dot map that specifies the location of human heads) with a diffusion model. We are also the first to use these diverse synthetic data to augment the crowd counting models. Our proposed smoothed density map input for ControlNet significantly improves ControlNet's performance in generating crowds in the correct locations. Also, Our proposed counting loss for the diffusion model effectively minimizes the discrepancies between the location dot map and the crowd images generated. Additionally, our innovative guidance sampling further directs the diffusion process toward regions where the generated crowd images align most accurately with the location dot map. Collectively, we have enhanced ControlNet's ability to generate specified objects from a location dot map, which can be used for data augmentation in various counting problems. Moreover, our framework is versatile and can be easily adapted to all kinds of counting problems. Extensive experiments demonstrate that our framework improves the counting performance on the ShanghaiTech, NWPU-Crowd, UCF-QNRF, and TRANCOS datasets, showcasing its effectiveness.
Real-to-Sim Deformable Object Manipulation: Optimizing Physics Models with Residual Mappings for Robotic Surgery
Sep 20, 2023Accurate deformable object manipulation (DOM) is essential for achieving autonomy in robotic surgery, where soft tissues are being displaced, stretched, and dissected. Many DOM methods can be powered by simulation, which ensures realistic deformation by adhering to the governing physical constraints and allowing for model prediction and control. However, real soft objects in robotic surgery, such as membranes and soft tissues, have complex, anisotropic physical parameters that a simulation with simple initialization from cameras may not fully capture. To use the simulation techniques in real surgical tasks, the "real-to-sim" gap needs to be properly compensated. In this work, we propose an online, adaptive parameter tuning approach for simulation optimization that (1) bridges the real-to-sim gap between a physics simulation and observations obtained 3D perceptions through estimating a residual mapping and (2) optimizes its stiffness parameters online. Our method ensures a small residual gap between the simulation and observation and improves the simulation's predictive capabilities. The effectiveness of the proposed mechanism is evaluated in the manipulation of both a thin-shell and volumetric tissue, representative of most tissue scenarios. This work contributes to the advancement of simulation-based deformable tissue manipulation and holds potential for improving surgical autonomy.