 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark on Extremely Weakly Supervised Text Classification: Reconcile Seed Matching and Prompting Approaches
Paper and Code
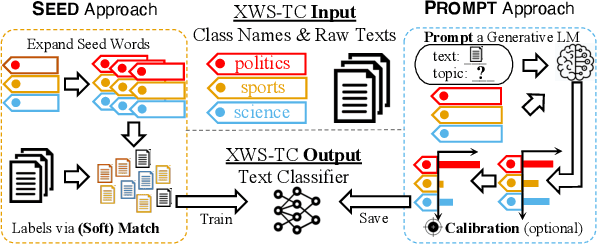
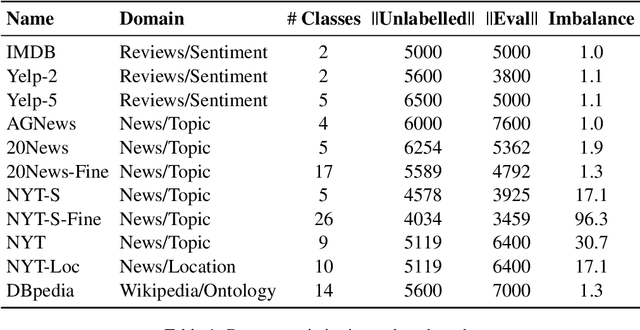
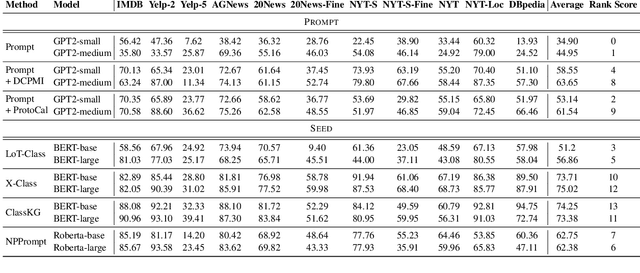
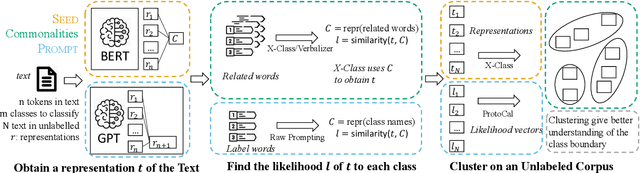
Etremely Weakly Supervised Text Classification (XWS-TC) refers to text classification based on minimal high-level human guidance, such as a few label-indicative seed words or classification instructions. There are two mainstream approaches for XWS-TC, however, never being rigorously compared: (1) training classifiers based on pseudo-labels generated by (softly) matching seed words (SEED) and (2) prompting (and calibrating) language models using classification instruction (and raw texts) to decode label words (PROMPT). This paper presents the first XWS-TC benchmark to compare the two approaches on fair grounds, where the datasets, supervisions, and hyperparameter choices are standardized across methods. Our benchmarking results suggest that (1) Both SEED and PROMPT approaches are competitive and there is no clear winner; (2) SEED is empirically more tolerant than PROMPT to human guidance (e.g., seed words, classification instructions, and label words) changes; (3) SEED is empirically more selective than PROMPT to the pre-trained language models; (4) Recent SEED and PROMPT methods have close connections and a clustering post-processing step based on raw in-domain texts is a strong performance booster to both. We hope this benchmark serves as a guideline in selecting XWS-TC methods in different scenarios and stimulate interest in developing guidance- and model-robust XWS-TC methods. We release the repo at https://github.com/ZihanWangKi/x-TC.