 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCityLLaVA: Efficient Fine-Tuning for VLMs in City Scenario
May 06, 2024



In the vast and dynamic landscape of urban settings, Traffic Safety Description and Analysis plays a pivotal role in applications ranging from insurance inspection to accident prevention. This paper introduces CityLLaVA, a novel fine-tuning framework for Visual Language Models (VLMs) designed for urban scenarios. CityLLaVA enhances model comprehension and prediction accuracy through (1) employing bounding boxes for optimal visual data preprocessing, including video best-view selection and visual prompt engineering during both training and testing phases; (2) constructing concise Question-Answer sequences and designing textual prompts to refine instruction comprehension; (3) implementing block expansion to fine-tune large VLMs efficiently; and (4) advancing prediction accuracy via a unique sequential questioning-based prediction augmentation. Demonstrating top-tier performance, our method achieved a benchmark score of 33.4308, securing the leading position on the leaderboard. The code can be found: https://github.com/alibaba/AICITY2024_Track2_AliOpenTrek_CityLLaVA
Chinese Sentences Similarity via Cross-Attention Based Siamese Network
May 06, 2021
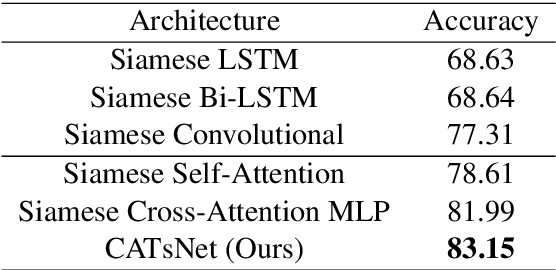

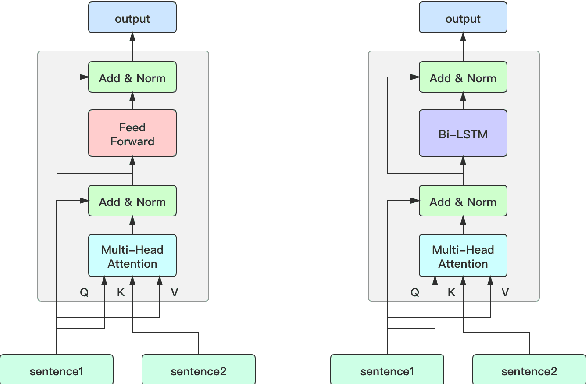
Measuring sentence similarity is a key research area nowadays as it allows machines to better understand human languages. In this paper, we proposed a Cross-Attention Siamese Network (CATsNet) to carry out the task of learning the semantic meanings of Chinese sentences and comparing the similarity between two sentences. This novel model is capable of catching non-local features. Additionally, we also tried to apply the long short-term memory (LSTM) network in the model to improve its performance. The experiments were conducted on the LCQMC dataset and the results showed that our model could achieve a higher accuracy than previous work.
Comparing Machine Learning Algorithms with or without Feature Extraction for DNA Classification
Nov 01, 2020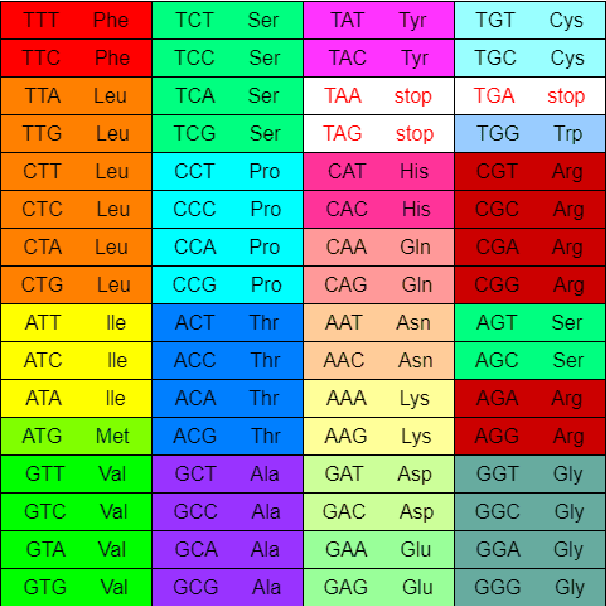

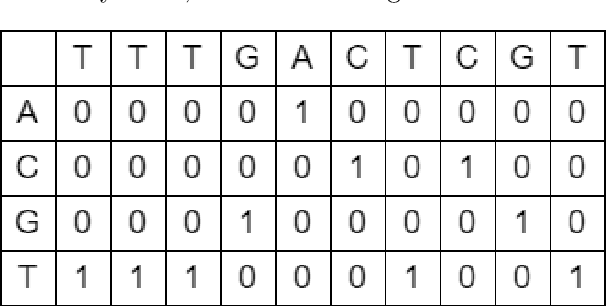

The classification of DNA sequences is a key research area in bioinformatics as it enables researchers to conduct genomic analysis and detect possible diseases. In this paper, three state-of-the-art algorithms, namely Convolutional Neural Networks, Deep Neural Networks, and N-gram Probabilistic Models, are used for the task of DNA classification. Furthermore, we introduce a novel feature extraction method based on the Levenshtein distance and randomly generated DNA sub-sequences to compute information-rich features from the DNA sequences. We also use an existing feature extraction method based on 3-grams to represent amino acids and combine both feature extraction methods with a multitude of machine learning algorithms. Four different data sets, each concerning viral diseases such as Covid-19, AIDS, Influenza, and Hepatitis C, are used for evaluating the different approaches. The results of the experiments show that all methods obtain high accuracies on the different DNA datasets. Furthermore, the domain-specific 3-gram feature extraction method leads in general to the best results in the experiments, while the newly proposed technique outperforms all other methods on the smallest Covid-19 dataset