 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Machine Learning Algorithms with or without Feature Extraction for DNA Classification
Nov 01, 2020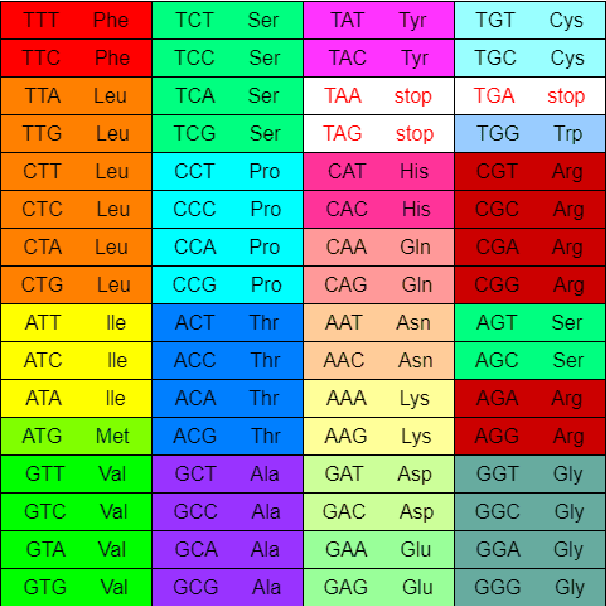

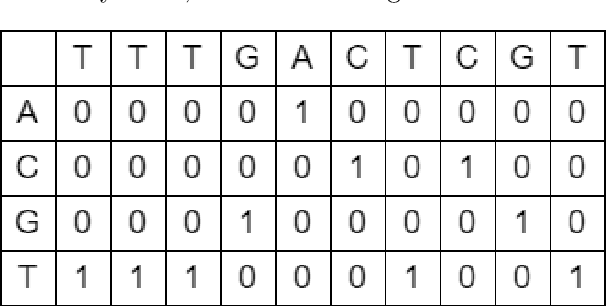

The classification of DNA sequences is a key research area in bioinformatics as it enables researchers to conduct genomic analysis and detect possible diseases. In this paper, three state-of-the-art algorithms, namely Convolutional Neural Networks, Deep Neural Networks, and N-gram Probabilistic Models, are used for the task of DNA classification. Furthermore, we introduce a novel feature extraction method based on the Levenshtein distance and randomly generated DNA sub-sequences to compute information-rich features from the DNA sequences. We also use an existing feature extraction method based on 3-grams to represent amino acids and combine both feature extraction methods with a multitude of machine learning algorithms. Four different data sets, each concerning viral diseases such as Covid-19, AIDS, Influenza, and Hepatitis C, are used for evaluating the different approaches. The results of the experiments show that all methods obtain high accuracies on the different DNA datasets. Furthermore, the domain-specific 3-gram feature extraction method leads in general to the best results in the experiments, while the newly proposed technique outperforms all other methods on the smallest Covid-19 dataset