 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Symbolic Reinforcement Learning with Landmark-Based Task Decomposition
Paper and Code


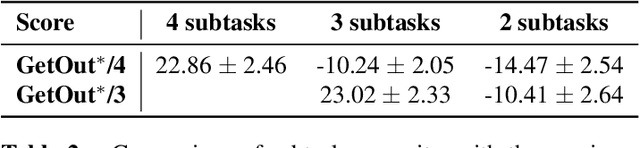

One of the fundamental challenges in reinforcement learning (RL) is to take a complex task and be able to decompose it to subtasks that are simpler for the RL agent to learn. In this paper, we report on our work that would identify subtasks by using some given positive and negative trajectories for solving the complex task. We assume that the states are represented by first-order predicate logic using which we devise a novel algorithm to identify the subtasks. Then we employ a Large Language Model (LLM) to generate first-order logic rule templates for achieving each subtask. Such rules were then further fined tuned to a rule-based policy via an Inductive Logic Programming (ILP)-based RL agent. Through experiments, we verify the accuracy of our algorithm in detecting subtasks which successfully detect all of the subtasks correctly. We also investigated the quality of the common-sense rules produced by the language model to achieve the subtasks. Our experiments show that our LLM-guided rule template generation can produce rules that are necessary for solving a subtask, which leads to solving complex tasks with fewer assumptions about predefined first-order logic predicates of the environment.