 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Model Empowered Streaming Semantic Communications for Speech Translation
Jan 10, 2025Semantic communications have been explored to perform downstream intelligent tasks by extracting and transmitting essential information. In this paper, we introduce a large model-empowered streaming semantic communication system for speech translation across various languages, named LaSC-ST. Specifically, we devise an edge-device collaborative semantic communication architecture by offloading the intricate semantic extraction module to edge servers, thereby reducing the computational burden on local devices. To support multilingual speech translation, pre-trained large speech models are utilized to learn unified semantic features from speech in different languages, breaking the constraint of a single input language and enhancing the practicality of the LaSC-ST. Moreover, the input speech is sequentially streamed into the developed system as short speech segments, which enables low transmission latency without the degradation in speech translation quality. A novel dynamic speech segmentation algorithm is proposed to further minimize the transmission latency by adaptively adjusting the duration of speech segments. According to simulation results, the LaSC-ST provides more accurate speech translation and achieves streaming transmission with lower latency compared to existing non-streaming semantic communication systems.
Semantic MIMO Systems for Speech-to-Text Transmission
May 13, 2024Semantic communications have been utilized to execute numerous intelligent tasks by transmitting task-related semantic information instead of bits. In this article, we propose a semantic-aware speech-to-text transmission system for the single-user multiple-input multiple-output (MIMO) and multi-user MIMO communication scenarios, named SAC-ST. Particularly, a semantic communication system to serve the speech-to-text task at the receiver is first designed, which compresses the semantic information and generates the low-dimensional semantic features by leveraging the transformer module. In addition, a novel semantic-aware network is proposed to facilitate the transmission with high semantic fidelity to identify the critical semantic information and guarantee it is recovered accurately. Furthermore, we extend the SAC-ST with a neural network-enabled channel estimation network to mitigate the dependence on accurate channel state information and validate the feasibility of SAC-ST in practical communication environments. Simulation results will show that the proposed SAC-ST outperforms the communication framework without the semantic-aware network for speech-to-text transmission over the MIMO channels in terms of the speech-to-text metrics, especially in the low signal-to-noise regime. Moreover, the SAC-ST with the developed channel estimation network is comparable to the SAC-ST with perfect channel state information.
Robust Semantic Communications for Speech-to-Text Translation
Mar 08, 2024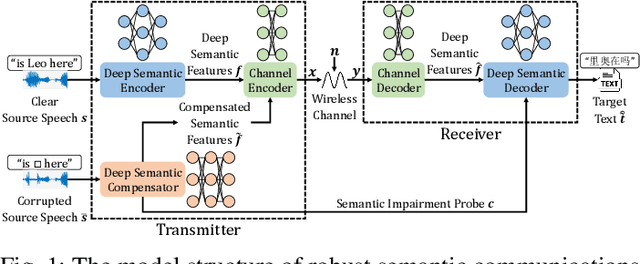
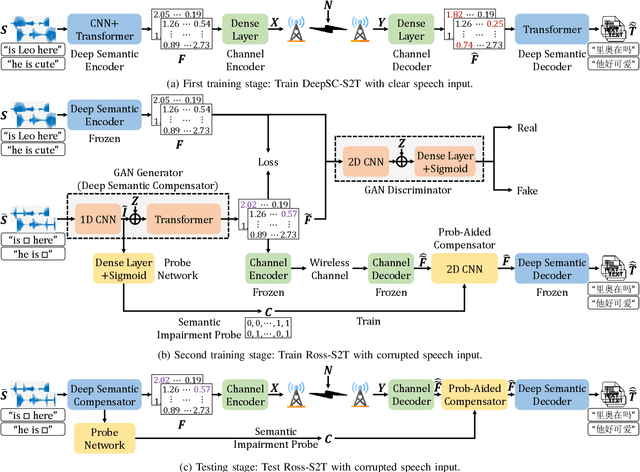
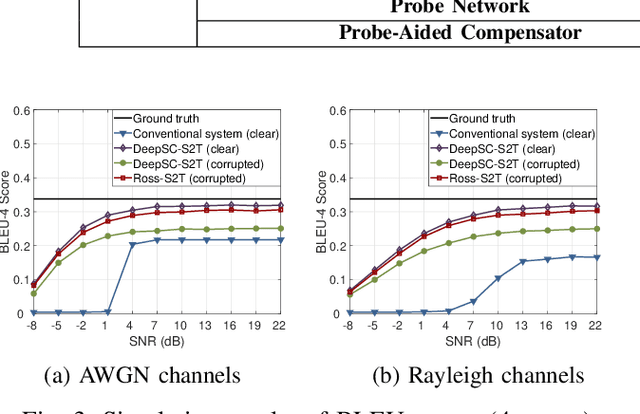
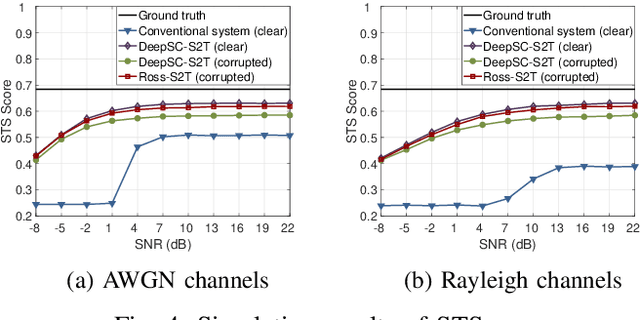
In this paper, we propose a robust semantic communication system to achieve the speech-to-text translation task, named Ross-S2T, by delivering the essential semantic information. Particularly, a deep semantic encoder is developed to directly condense and convert the speech in the source language to the textual semantic features associated with the target language, thus encouraging the design of a deep learning-enabled semantic communication system for speech-to-text translation that can be jointly trained in an end-to-end manner. Moreover, to cope with the practical communication scenario when the input speech is corrupted, a novel generative adversarial network (GAN)-enabled deep semantic compensator is proposed to predict the lost semantic information in the source speech and produce the textual semantic features in the target language simultaneously, which establishes a robust semantic transmission mechanism for dynamic speech input. According to the simulation results, the proposed Ross-S2T achieves significant speech-to-text translation performance compared to the conventional approach and exhibits high robustness against the corrupted speech input.
Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis
May 09, 2022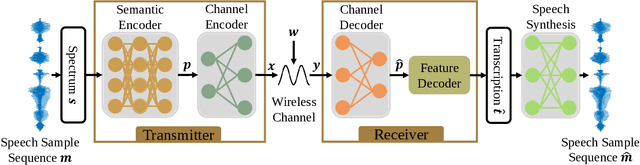

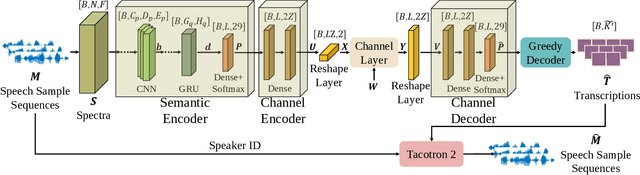
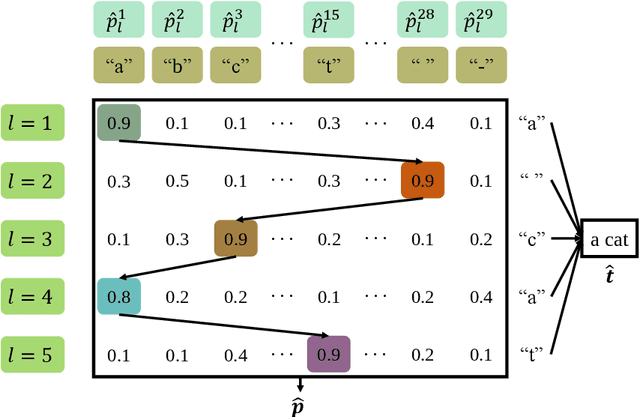
In this paper, we develop a deep learning based semantic communication system for speech transmission, named DeepSC-ST. We take the speech recognition and speech synthesis as the transmission tasks of the communication system, respectively. First, the speech recognition-related semantic features are extracted for transmission by a joint semantic-channel encoder and the text is recovered at the receiver based on the received semantic features, which significantly reduces the required amount of data transmission without performance degradation. Then, we perform speech synthesis at the receiver, which dedicates to re-generate the speech signals by feeding the recognized text transcription into a neural network based speech synthesis module. To enable the DeepSC-ST adaptive to dynamic channel environments, we identify a robust model to cope with different channel conditions. According to the simulation results, the proposed DeepSC-ST significantly outperforms conventional communication systems, especially in the low signal-to-noise ratio (SNR) regime. A demonstration is further developed as a proof-of-concept of the DeepSC-ST.
Semantic Communications for Speech Recognition
Jul 22, 2021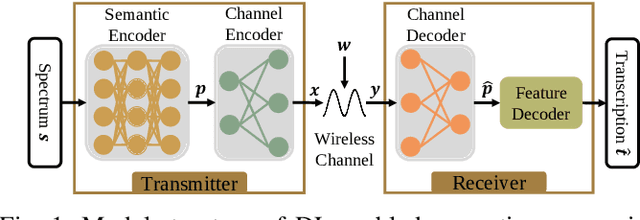
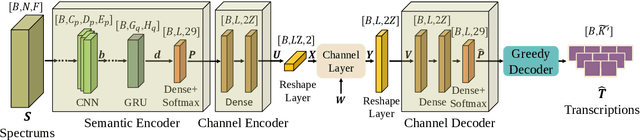
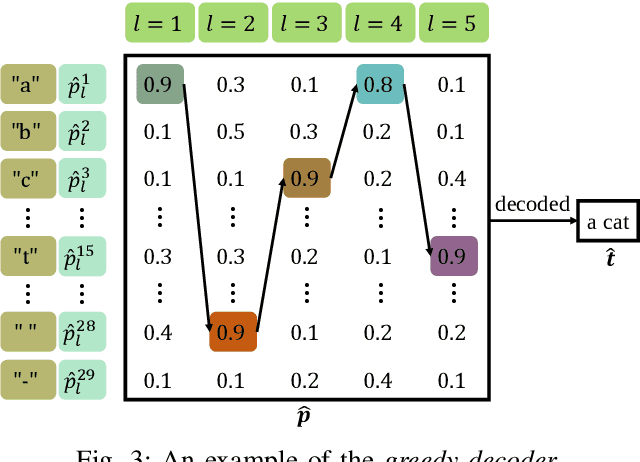
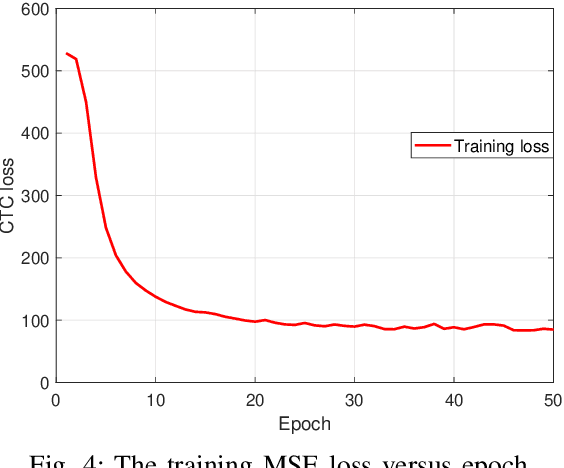
The traditional communications transmit all the source date represented by bits, regardless of the content of source and the semantic information required by the receiver. However, in some applications, the receiver only needs part of the source data that represents critical semantic information, which prompts to transmit the application-related information, especially when bandwidth resources are limited. In this paper, we consider a semantic communication system for speech recognition by designing the transceiver as an end-to-end (E2E) system. Particularly, a deep learning (DL)-enabled semantic communication system, named DeepSC-SR, is developed to learn and extract text-related semantic features at the transmitter, which motivates the system to transmit much less than the source speech data without performance degradation. Moreover, in order to facilitate the proposed DeepSC-SR for dynamic channel environments, we investigate a robust model to cope with various channel environments without requiring retraining. The simulation results demonstrate that our proposed DeepSC-SR outperforms the traditional communication systems in terms of the speech recognition metrics, such as character-error-rate and word-error-rate, and is more robust to channel variations, especially in the low signal-to-noise (SNR) regime.
Semantic Communication Systems for Speech Transmission
Feb 24, 2021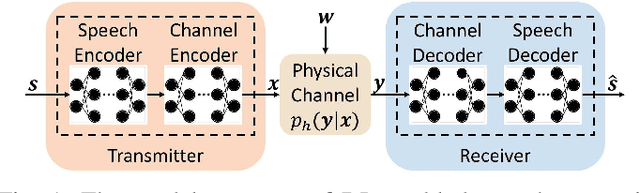



Semantic communications could improve the transmission efficiency significantly by exploring the input semantic information. Motivated by the breakthroughs in deep learning (DL), we make an effort to recover the transmitted speech signals in the semantic communication systems, which minimizes the error at the semantic level rather than the bit level or symbol level as in the traditional communication systems. Particularly, we design a DL-enabled semantic communication system for speech signals, named DeepSC-S. Based on an attention mechanism employing squeeze-and-excitation (SE) networks, DeepSC-S is able to identify the essential speech information and assign high values to the weights corresponding to the essential information when training the neural network. Moreover, in order to facilitate the proposed DeepSC-S to cater to dynamic channel environments, we dedicate to find a general model to cope with various channel conditions without retraining. Furthermore, to verify the model adaptation in practice, we investigate DeepSC-S in the telephone systems as well as the multimedia transmission systems, which usually requires higher data rates and lower transmission latency. The simulation results demonstrate that our proposed DeepSC-S achieves higher system performance than the traditional communications in both telephone systems and multimedia transmission systems by comparing the speech signals metrics, signal-to-distortion ration and perceptual evaluation of speech distortion. Besides, DeepSC-S is more robust to channel variations than the traditional approaches, especially in the low signal-to-noise (SNR) regime.