 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriniMark: A Robust Generative Speech Watermarking Method for Trinity-Level Attribution
Apr 29, 2025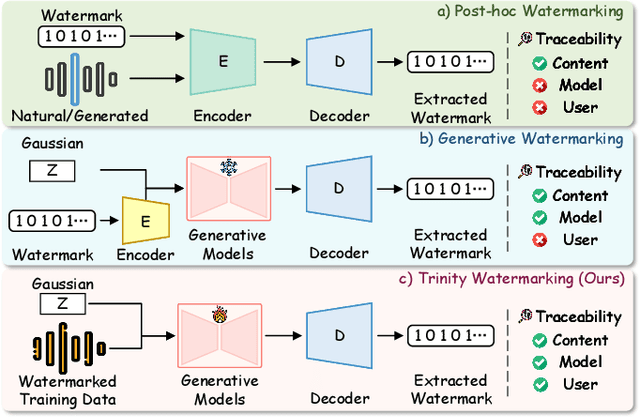
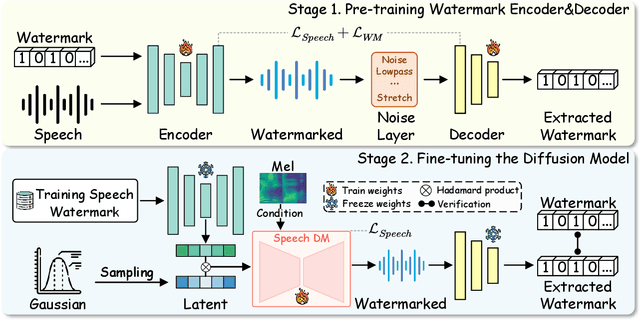
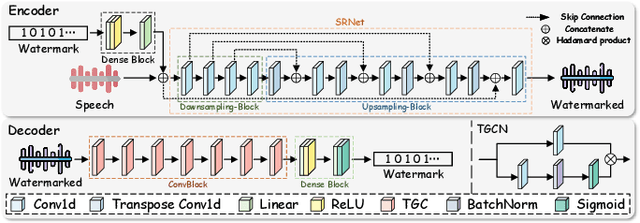
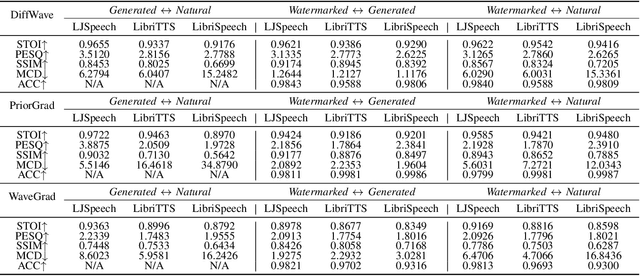
The emergence of diffusion models has facilitated the generation of speech with reinforced fidelity and naturalness. While deepfake detection technologies have manifested the ability to identify AI-generated content, their efficacy decreases as generative models become increasingly sophisticated. Furthermore, current research in the field has not adequately addressed the necessity for robust watermarking to safeguard the intellectual property rights associated with synthetic speech and generative models. To remedy this deficiency, we propose a \textbf{ro}bust generative \textbf{s}peech wat\textbf{e}rmarking method (TriniMark) for authenticating the generated content and safeguarding the copyrights by enabling the traceability of the diffusion model. We first design a structure-lightweight watermark encoder that embeds watermarks into the time-domain features of speech and reconstructs the waveform directly. A temporal-aware gated convolutional network is meticulously designed in the watermark decoder for bit-wise watermark recovery. Subsequently, the waveform-guided fine-tuning strategy is proposed for fine-tuning the diffusion model, which leverages the transferability of watermarks and enables the diffusion model to incorporate watermark knowledge effectively. When an attacker trains a surrogate model using the outputs of the target model, the embedded watermark can still be learned by the surrogate model and correctly extracted. Comparative experiments with state-of-the-art methods demonstrate the superior robustness of our method, particularly in countering compound attacks.
Protecting Your Voice: Temporal-aware Robust Watermarking
Apr 21, 2025



The rapid advancement of generative models has led to the synthesis of real-fake ambiguous voices. To erase the ambiguity, embedding watermarks into the frequency-domain features of synthesized voices has become a common routine. However, the robustness achieved by choosing the frequency domain often comes at the expense of fine-grained voice features, leading to a loss of fidelity. Maximizing the comprehensive learning of time-domain features to enhance fidelity while maintaining robustness, we pioneer a \textbf{\underline{t}}emporal-aware \textbf{\underline{r}}ob\textbf{\underline{u}}st wat\textbf{\underline{e}}rmarking (\emph{True}) method for protecting the speech and singing voice.
SOLIDO: A Robust Watermarking Method for Speech Synthesis via Low-Rank Adaptation
Apr 21, 2025



The accelerated advancement of speech generative models has given rise to security issues, including model infringement and unauthorized abuse of content. Although existing generative watermarking techniques have proposed corresponding solutions, most methods require substantial computational overhead and training costs. In addition, some methods have limitations in robustness when handling variable-length inputs. To tackle these challenges, we propose \textsc{SOLIDO}, a novel generative watermarking method that integrates parameter-efficient fine-tuning with speech watermarking through low-rank adaptation (LoRA) for speech diffusion models. Concretely, the watermark encoder converts the watermark to align with the input of diffusion models. To achieve precise watermark extraction from variable-length inputs, the watermark decoder based on depthwise separable convolution is designed for watermark recovery. To further enhance speech generation performance and watermark extraction capability, we propose a speech-driven lightweight fine-tuning strategy, which reduces computational overhead through LoRA. Comprehensive experiments demonstrate that the proposed method ensures high-fidelity watermarked speech even at a large capacity of 2000 bps. Furthermore, against common individual and compound speech attacks, our SOLIDO achieves a maximum average extraction accuracy of 99.20\% and 98.43\%, respectively. It surpasses other state-of-the-art methods by nearly 23\% in resisting time-stretching attacks.
An Efficient Watermarking Method for Latent Diffusion Models via Low-Rank Adaptation
Oct 26, 2024The rapid proliferation of deep neural networks (DNNs) is driving a surge in model watermarking technologies, as the trained deep models themselves serve as intellectual properties. The core of existing model watermarking techniques involves modifying or tuning the models' weights. However, with the emergence of increasingly complex models, ensuring the efficiency of watermarking process is essential to manage the growing computational demands. Prioritizing efficiency not only optimizes resource utilization, making the watermarking process more applicable, but also minimizes potential impacts on model performance. In this letter, we propose an efficient watermarking method for latent diffusion models (LDMs) which is based on Low-Rank Adaptation (LoRA). We specifically choose to add trainable low-rank matrices to the existing weight matrices of the models to embed watermark, while keeping the original weights frozen. Moreover, we also propose a dynamic loss weight tuning algorithm to balance the generative task with the watermark embedding task, ensuring that the model can be watermarked with a limited impact on the quality of the generated images. Experimental results show that the proposed method ensures fast watermark embedding and maintains a very low bit error rate of the watermark, a high-quality of the generated image, and a zero false negative rate (FNR) for verification.
GROOT: Generating Robust Watermark for Diffusion-Model-Based Audio Synthesis
Jul 15, 2024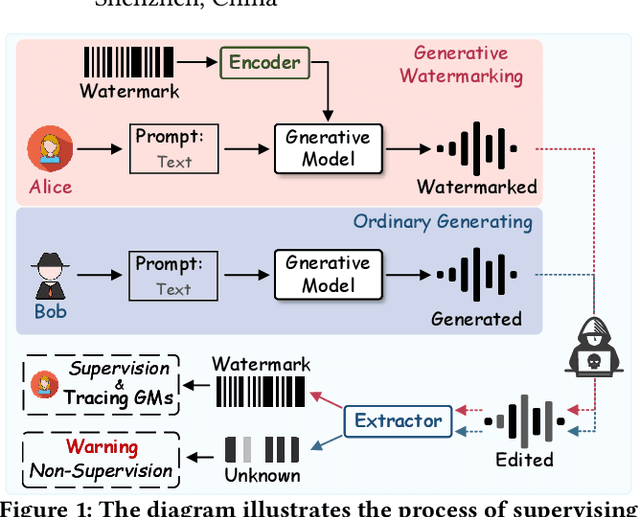
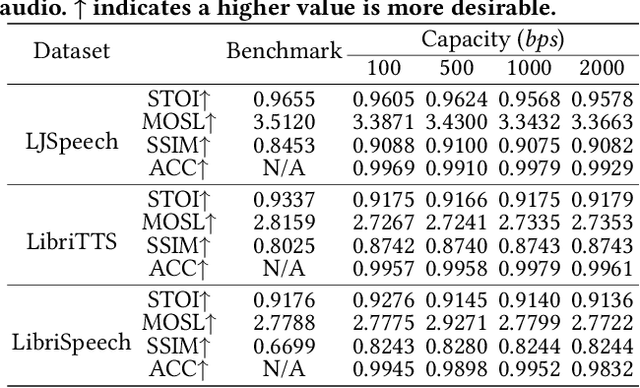
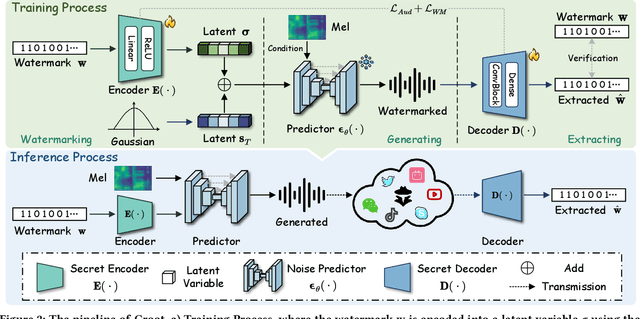
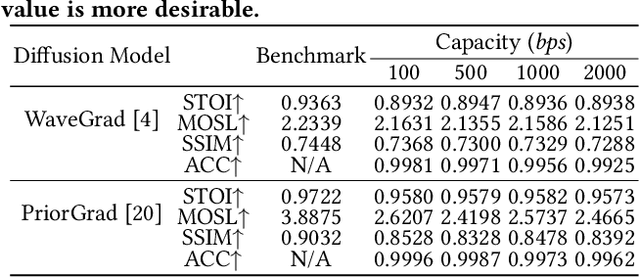
Amid the burgeoning development of generative models like diffusion models, the task of differentiating synthesized audio from its natural counterpart grows more daunting. Deepfake detection offers a viable solution to combat this challenge. Yet, this defensive measure unintentionally fuels the continued refinement of generative models. Watermarking emerges as a proactive and sustainable tactic, preemptively regulating the creation and dissemination of synthesized content. Thus, this paper, as a pioneer, proposes the generative robust audio watermarking method (Groot), presenting a paradigm for proactively supervising the synthesized audio and its source diffusion models. In this paradigm, the processes of watermark generation and audio synthesis occur simultaneously, facilitated by parameter-fixed diffusion models equipped with a dedicated encoder. The watermark embedded within the audio can subsequently be retrieved by a lightweight decoder. The experimental results highlight Groot's outstanding performance, particularly in terms of robustness, surpassing that of the leading state-of-the-art methods. Beyond its impressive resilience against individual post-processing attacks, Groot exhibits exceptional robustness when facing compound attacks, maintaining an average watermark extraction accuracy of around 95%.
Nanoscale Microscopy Images Colourisation Using Neural Networks
Dec 17, 2019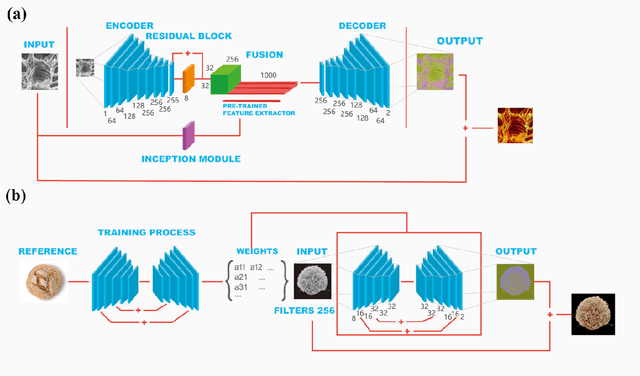
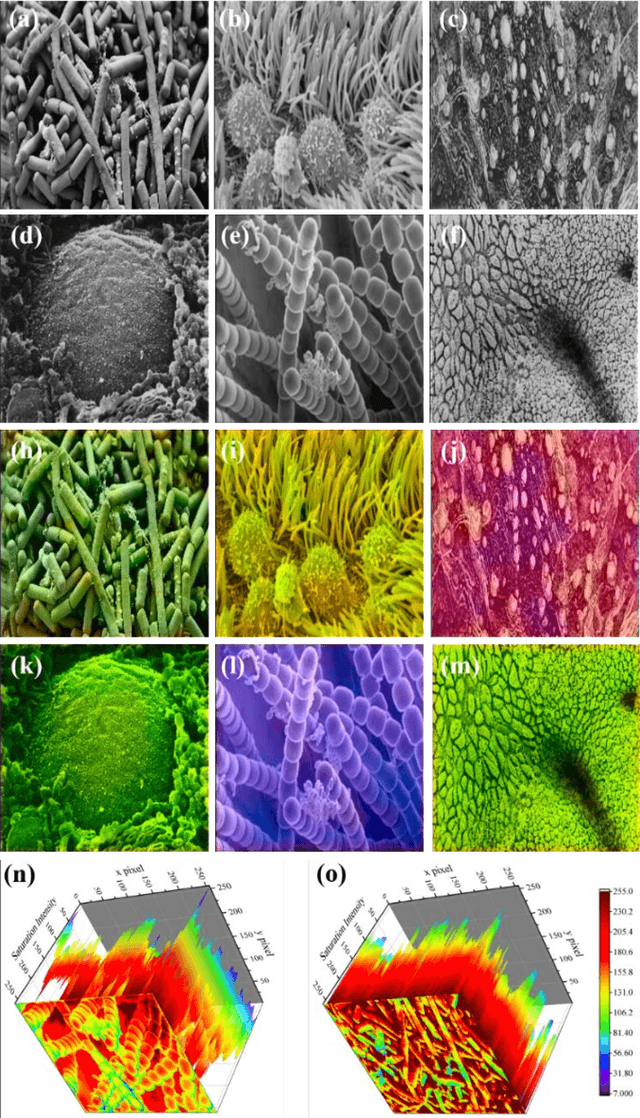


Microscopy images are powerful tools and widely used in the majority of research areas, such as biology, chemistry, physics and materials fields by various microscopies (Scanning Electron Microscope (SEM), Atomic Force Microscope (AFM) and the optical microscope, et al.). However, most of the microscopy images are colourless due to the unique imaging mechanism. Though investigating on some popular solutions proposed recently about colourizing microscopy images, we notice the process of those methods are usually tedious, complicated, and time-consuming. In this paper, inspired by the achievement of machine learning algorithms on different science fields, we introduce two artificial neural networks for grey microscopy image colourization: An end-to-end convolutional neural network (CNN) with a pre-trained model for feature extraction and a pixel-to-pixel Neural Style Transfer convolutional neural network (NST-CNN) which can colourize grey microscopy images with semantic information learned from a user-provided colour image at inference time. Our results show that our algorithm not only could able to colour the microscopy images under complex circumstances precisely but also make the colour naturally according to a massive number of nature images training with proper hue and saturation.