 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023



This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo
Replacing Labeled Real-image Datasets with Auto-generated Contours
Jun 18, 2022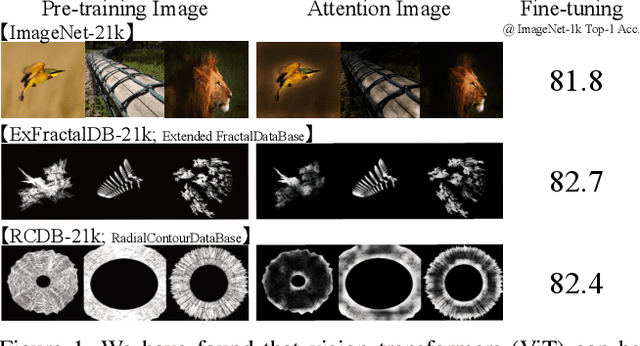
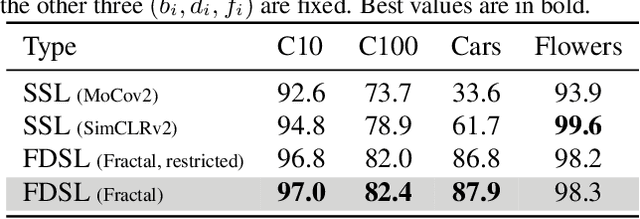

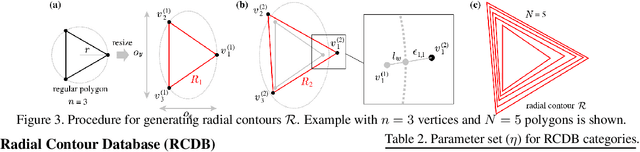
In the present work, we show that the performance of formula-driven supervised learning (FDSL) can match or even exceed that of ImageNet-21k without the use of real images, human-, and self-supervision during the pre-training of Vision Transformers (ViTs). For example, ViT-Base pre-trained on ImageNet-21k shows 81.8% top-1 accuracy when fine-tuned on ImageNet-1k and FDSL shows 82.7% top-1 accuracy when pre-trained under the same conditions (number of images, hyperparameters, and number of epochs). Images generated by formulas avoid the privacy/copyright issues, labeling cost and errors, and biases that real images suffer from, and thus have tremendous potential for pre-training general models. To understand the performance of the synthetic images, we tested two hypotheses, namely (i) object contours are what matter in FDSL datasets and (ii) increased number of parameters to create labels affects performance improvement in FDSL pre-training. To test the former hypothesis, we constructed a dataset that consisted of simple object contour combinations. We found that this dataset can match the performance of fractals. For the latter hypothesis, we found that increasing the difficulty of the pre-training task generally leads to better fine-tuning accuracy.