 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFL: A Self-Attention Scene Text Recognizer with Focal Loss
Jan 01, 2022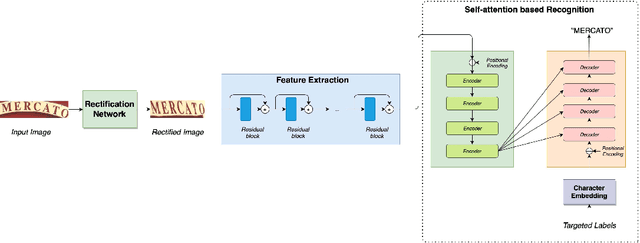
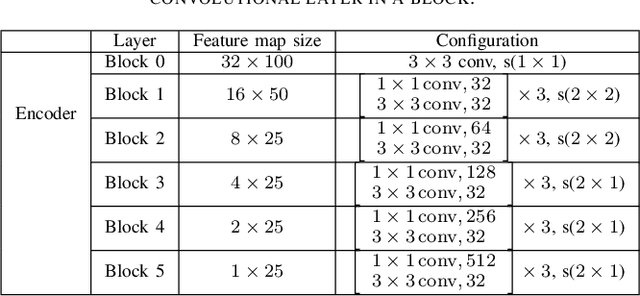

In the last decades, scene text recognition has gained worldwide attention from both the academic community and actual users due to its importance in a wide range of applications. Despite achievements in optical character recognition, scene text recognition remains challenging due to inherent problems such as distortions or irregular layout. Most of the existing approaches mainly leverage recurrence or convolution-based neural networks. However, while recurrent neural networks (RNNs) usually suffer from slow training speed due to sequential computation and encounter problems as vanishing gradient or bottleneck, CNN endures a trade-off between complexity and performance. In this paper, we introduce SAFL, a self-attention-based neural network model with the focal loss for scene text recognition, to overcome the limitation of the existing approaches. The use of focal loss instead of negative log-likelihood helps the model focus more on low-frequency samples training. Moreover, to deal with the distortions and irregular texts, we exploit Spatial TransformerNetwork (STN) to rectify text before passing to the recognition network. We perform experiments to compare the performance of the proposed model with seven benchmarks. The numerical results show that our model achieves the best performance.
* Accepted to ICMLA 2020