 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBluRef: Unsupervised Image Deblurring with Dense-Matching References
Mar 15, 2026This paper introduces a novel unsupervised approach for image deblurring that utilizes a simple process for training data collection, thereby enhancing the applicability and effectiveness of deblurring methods. Our technique does not require meticulously paired data of blurred and corresponding sharp images; instead, it uses unpaired blurred and sharp images of similar scenes to generate pseudo-ground truth data by leveraging a dense matching model to identify correspondences between a blurry image and reference sharp images. Thanks to the simplicity of the training data collection process, our approach does not rely on existing paired training data or pre-trained networks, making it more adaptable to various scenarios and suitable for networks of different sizes, including those designed for low-resource devices. We demonstrate that this novel approach achieves state-of-the-art performance, marking a significant advancement in the field of image deblurring.
Blur2Blur: Blur Conversion for Unsupervised Image Deblurring on Unknown Domains
Mar 24, 2024

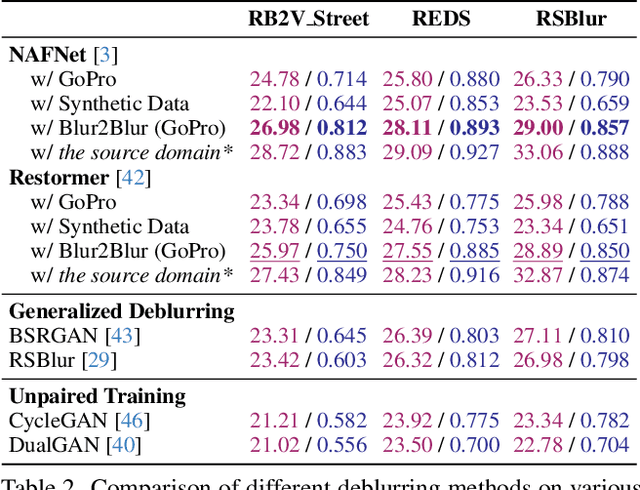

This paper presents an innovative framework designed to train an image deblurring algorithm tailored to a specific camera device. This algorithm works by transforming a blurry input image, which is challenging to deblur, into another blurry image that is more amenable to deblurring. The transformation process, from one blurry state to another, leverages unpaired data consisting of sharp and blurry images captured by the target camera device. Learning this blur-to-blur transformation is inherently simpler than direct blur-to-sharp conversion, as it primarily involves modifying blur patterns rather than the intricate task of reconstructing fine image details. The efficacy of the proposed approach has been demonstrated through comprehensive experiments on various benchmarks, where it significantly outperforms state-of-the-art methods both quantitatively and qualitatively. Our code and data are available at https://zero1778.github.io/blur2blur/
HyperCUT: Video Sequence from a Single Blurry Image using Unsupervised Ordering
Apr 05, 2023
We consider the challenging task of training models for image-to-video deblurring, which aims to recover a sequence of sharp images corresponding to a given blurry image input. A critical issue disturbing the training of an image-to-video model is the ambiguity of the frame ordering since both the forward and backward sequences are plausible solutions. This paper proposes an effective self-supervised ordering scheme that allows training high-quality image-to-video deblurring models. Unlike previous methods that rely on order-invariant losses, we assign an explicit order for each video sequence, thus avoiding the order-ambiguity issue. Specifically, we map each video sequence to a vector in a latent high-dimensional space so that there exists a hyperplane such that for every video sequence, the vectors extracted from it and its reversed sequence are on different sides of the hyperplane. The side of the vectors will be used to define the order of the corresponding sequence. Last but not least, we propose a real-image dataset for the image-to-video deblurring problem that covers a variety of popular domains, including face, hand, and street. Extensive experimental results confirm the effectiveness of our method. Code and data are available at https://github.com/VinAIResearch/HyperCUT.git