 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Matching Using Hypernetwork-Based Kolmogorov-Arnold Networks
Mar 14, 2025We present cmKAN, a versatile framework for color matching. Given an input image with colors from a source color distribution, our method effectively and accurately maps these colors to match a target color distribution in both supervised and unsupervised settings. Our framework leverages the spline capabilities of Kolmogorov-Arnold Networks (KANs) to model the color matching between source and target distributions. Specifically, we developed a hypernetwork that generates spatially varying weight maps to control the nonlinear splines of a KAN, enabling accurate color matching. As part of this work, we introduce a first large-scale dataset of paired images captured by two distinct cameras and evaluate the efficacy of our and existing methods in matching colors. We evaluated our approach across various color-matching tasks, including: (1) raw-to-raw mapping, where the source color distribution is in one camera's raw color space and the target in another camera's raw space; (2) raw-to-sRGB mapping, where the source color distribution is in a camera's raw space and the target is in the display sRGB space, emulating the color rendering of a camera ISP; and (3) sRGB-to-sRGB mapping, where the goal is to transfer colors from a source sRGB space (e.g., produced by a source camera ISP) to a target sRGB space (e.g., from a different camera ISP). The results show that our method outperforms existing approaches by 37.3% on average for supervised and unsupervised cases while remaining lightweight compared to other methods. The codes, dataset, and pre-trained models are available at: https://github.com/gosha20777/cmKAN
HyperKAN: Kolmogorov-Arnold Networks make Hyperspectral Image Classificators Smarter
Jul 07, 2024



In traditional neural network architectures, a multilayer perceptron (MLP) is typically employed as a classification block following the feature extraction stage. However, the Kolmogorov-Arnold Network (KAN) presents a promising alternative to MLP, offering the potential to enhance prediction accuracy. In this paper, we propose the replacement of linear and convolutional layers of traditional networks with KAN-based counterparts. These modifications allowed us to significantly increase the per-pixel classification accuracy for hyperspectral remote-sensing images. We modified seven different neural network architectures for hyperspectral image classification and observed a substantial improvement in the classification accuracy across all the networks. The architectures considered in the paper include baseline MLP, state-of-the-art 1D (1DCNN) and 3D convolutional (two different 3DCNN, NM3DCNN), and transformer (SSFTT) architectures, as well as newly proposed M1DCNN. The greatest effect was achieved for convolutional networks working exclusively on spectral data, and the best classification quality was achieved using a KAN-based transformer architecture. All the experiments were conducted using seven openly available hyperspectral datasets. Our code is available at https://github.com/f-neumann77/HyperKAN.
Illumination Estimation Challenge: experience of past two years
Dec 31, 2020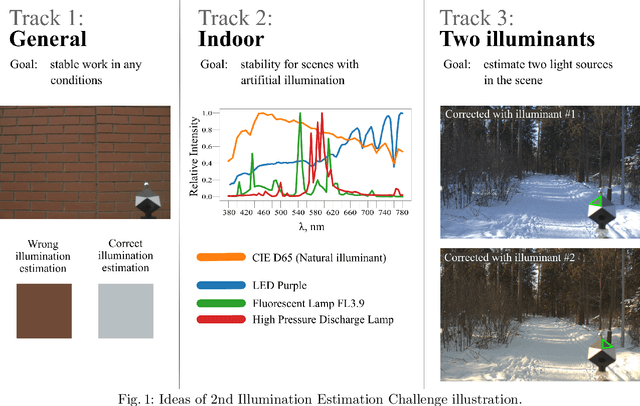
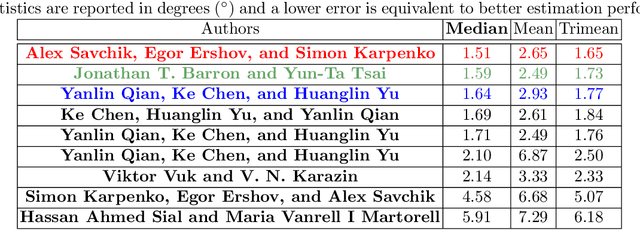

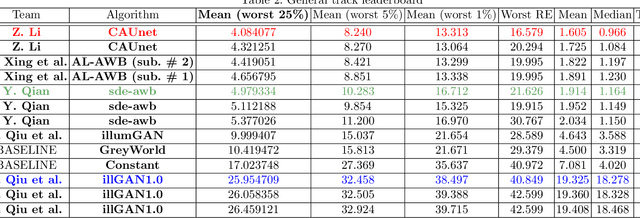
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.