 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuwatBench: Bridging Language and Visual Heritage through an Arabic Calligraphy Benchmark for Multimodal Understanding
Jan 27, 2026Arabic calligraphy represents one of the richest visual traditions of the Arabic language, blending linguistic meaning with artistic form. Although multimodal models have advanced across languages, their ability to process Arabic script, especially in artistic and stylized calligraphic forms, remains largely unexplored. To address this gap, we present DuwatBench, a benchmark of 1,272 curated samples containing about 1,475 unique words across six classical and modern calligraphic styles, each paired with sentence-level detection annotations. The dataset reflects real-world challenges in Arabic writing, such as complex stroke patterns, dense ligatures, and stylistic variations that often challenge standard text recognition systems. Using DuwatBench, we evaluated 13 leading Arabic and multilingual multimodal models and showed that while they perform well on clean text, they struggle with calligraphic variation, artistic distortions, and precise visual-text alignment. By publicly releasing DuwatBench and its annotations, we aim to advance culturally grounded multimodal research, foster fair inclusion of the Arabic language and visual heritage in AI systems, and support continued progress in this area. Our dataset (https://huggingface.co/datasets/MBZUAI/DuwatBench) and evaluation suit (https://github.com/mbzuai-oryx/DuwatBench) are publicly available.
Fann or Flop: A Multigenre, Multiera Benchmark for Arabic Poetry Understanding in LLMs
May 26, 2025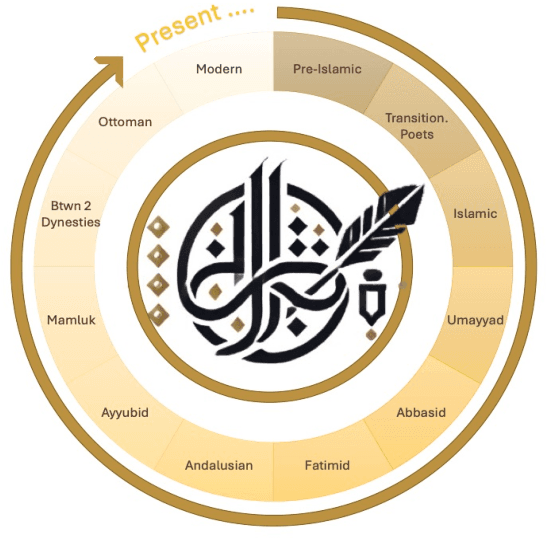
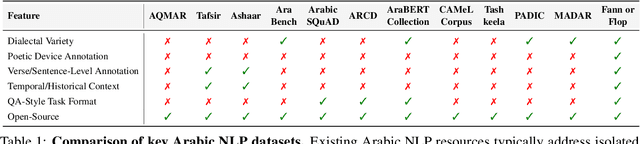
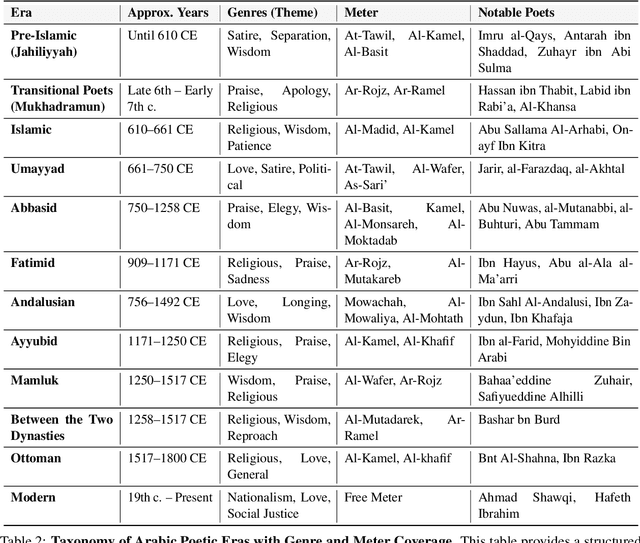
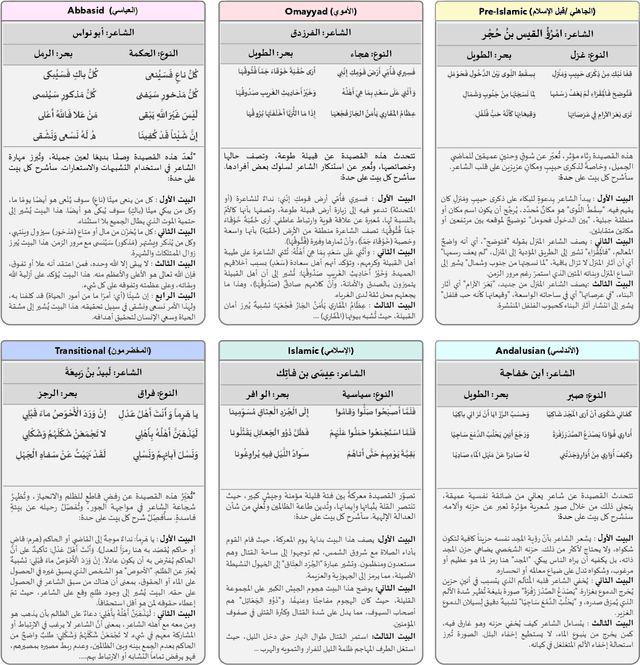
Arabic poetry is one of the richest and most culturally rooted forms of expression in the Arabic language, known for its layered meanings, stylistic diversity, and deep historical continuity. Although large language models (LLMs) have demonstrated strong performance across languages and tasks, their ability to understand Arabic poetry remains largely unexplored. In this work, we introduce \emph{Fann or Flop}, the first benchmark designed to assess the comprehension of Arabic poetry by LLMs in 12 historical eras, covering 14 core poetic genres and a variety of metrical forms, from classical structures to contemporary free verse. The benchmark comprises a curated corpus of poems with explanations that assess semantic understanding, metaphor interpretation, prosodic awareness, and cultural context. We argue that poetic comprehension offers a strong indicator for testing how good the LLM understands classical Arabic through Arabic poetry. Unlike surface-level tasks, this domain demands deeper interpretive reasoning and cultural sensitivity. Our evaluation of state-of-the-art LLMs shows that most models struggle with poetic understanding despite strong results on standard Arabic benchmarks. We release "Fann or Flop" along with the evaluation suite as an open-source resource to enable rigorous evaluation and advancement for Arabic language models. Code is available at: https://github.com/mbzuai-oryx/FannOrFlop.
ARB: A Comprehensive Arabic Multimodal Reasoning Benchmark
May 22, 2025
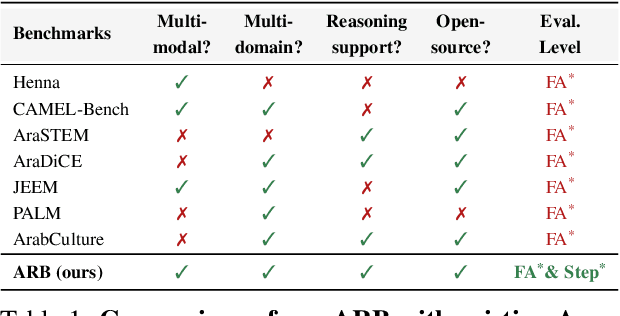
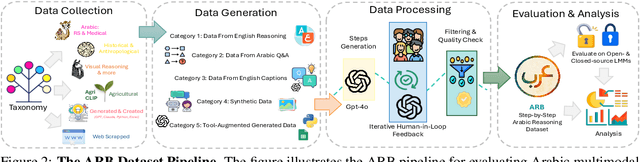
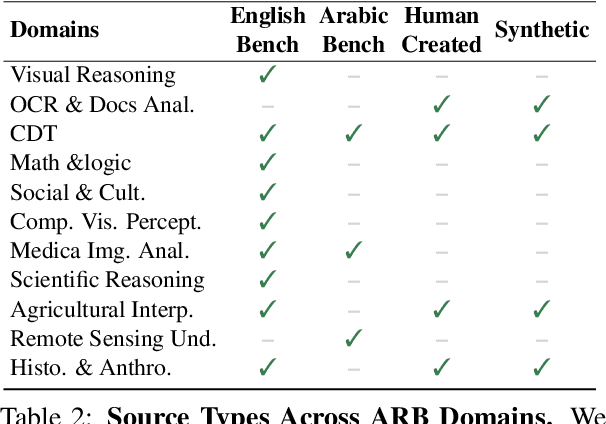
As Large Multimodal Models (LMMs) become more capable, there is growing interest in evaluating their reasoning processes alongside their final outputs. However, most benchmarks remain focused on English, overlooking languages with rich linguistic and cultural contexts, such as Arabic. To address this gap, we introduce the Comprehensive Arabic Multimodal Reasoning Benchmark (ARB), the first benchmark designed to evaluate step-by-step reasoning in Arabic across both textual and visual modalities. ARB spans 11 diverse domains, including visual reasoning, document understanding, OCR, scientific analysis, and cultural interpretation. It comprises 1,356 multimodal samples paired with 5,119 human-curated reasoning steps and corresponding actions. We evaluated 12 state-of-the-art open- and closed-source LMMs and found persistent challenges in coherence, faithfulness, and cultural grounding. ARB offers a structured framework for diagnosing multimodal reasoning in underrepresented languages and marks a critical step toward inclusive, transparent, and culturally aware AI systems. We release the benchmark, rubric, and evaluation suit to support future research and reproducibility. Code available at: https://github.com/mbzuai-oryx/ARB
Time Travel: A Comprehensive Benchmark to Evaluate LMMs on Historical and Cultural Artifacts
Feb 20, 2025Understanding historical and cultural artifacts demands human expertise and advanced computational techniques, yet the process remains complex and time-intensive. While large multimodal models offer promising support, their evaluation and improvement require a standardized benchmark. To address this, we introduce TimeTravel, a benchmark of 10,250 expert-verified samples spanning 266 distinct cultures across 10 major historical regions. Designed for AI-driven analysis of manuscripts, artworks, inscriptions, and archaeological discoveries, TimeTravel provides a structured dataset and robust evaluation framework to assess AI models' capabilities in classification, interpretation, and historical comprehension. By integrating AI with historical research, TimeTravel fosters AI-powered tools for historians, archaeologists, researchers, and cultural tourists to extract valuable insights while ensuring technology contributes meaningfully to historical discovery and cultural heritage preservation. We evaluate contemporary AI models on TimeTravel, highlighting their strengths and identifying areas for improvement. Our goal is to establish AI as a reliable partner in preserving cultural heritage, ensuring that technological advancements contribute meaningfully to historical discovery. Our code is available at: \url{https://github.com/mbzuai-oryx/TimeTravel}.
CAMEL-Bench: A Comprehensive Arabic LMM Benchmark
Oct 24, 2024Recent years have witnessed a significant interest in developing large multimodal models (LMMs) capable of performing various visual reasoning and understanding tasks. This has led to the introduction of multiple LMM benchmarks to evaluate LMMs on different tasks. However, most existing LMM evaluation benchmarks are predominantly English-centric. In this work, we develop a comprehensive LMM evaluation benchmark for the Arabic language to represent a large population of over 400 million speakers. The proposed benchmark, named CAMEL-Bench, comprises eight diverse domains and 38 sub-domains including, multi-image understanding, complex visual perception, handwritten document understanding, video understanding, medical imaging, plant diseases, and remote sensing-based land use understanding to evaluate broad scenario generalizability. Our CAMEL-Bench comprises around 29,036 questions that are filtered from a larger pool of samples, where the quality is manually verified by native speakers to ensure reliable model assessment. We conduct evaluations of both closed-source, including GPT-4 series, and open-source LMMs. Our analysis reveals the need for substantial improvement, especially among the best open-source models, with even the closed-source GPT-4o achieving an overall score of 62%. Our benchmark and evaluation scripts are open-sourced.