 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKITAB-Bench: A Comprehensive Multi-Domain Benchmark for Arabic OCR and Document Understanding
Feb 20, 2025With the growing adoption of Retrieval-Augmented Generation (RAG) in document processing, robust text recognition has become increasingly critical for knowledge extraction. While OCR (Optical Character Recognition) for English and other languages benefits from large datasets and well-established benchmarks, Arabic OCR faces unique challenges due to its cursive script, right-to-left text flow, and complex typographic and calligraphic features. We present KITAB-Bench, a comprehensive Arabic OCR benchmark that fills the gaps in current evaluation systems. Our benchmark comprises 8,809 samples across 9 major domains and 36 sub-domains, encompassing diverse document types including handwritten text, structured tables, and specialized coverage of 21 chart types for business intelligence. Our findings show that modern vision-language models (such as GPT-4, Gemini, and Qwen) outperform traditional OCR approaches (like EasyOCR, PaddleOCR, and Surya) by an average of 60% in Character Error Rate (CER). Furthermore, we highlight significant limitations of current Arabic OCR models, particularly in PDF-to-Markdown conversion, where the best model Gemini-2.0-Flash achieves only 65% accuracy. This underscores the challenges in accurately recognizing Arabic text, including issues with complex fonts, numeral recognition errors, word elongation, and table structure detection. This work establishes a rigorous evaluation framework that can drive improvements in Arabic document analysis methods and bridge the performance gap with English OCR technologies.
Gestalt: a Stacking Ensemble for SQuAD2.0
Apr 02, 2020
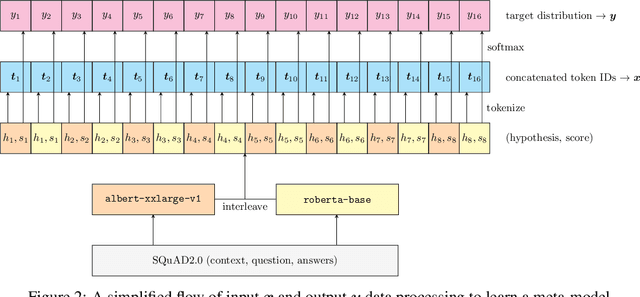

We propose a deep-learning system -- for the SQuAD2.0 task -- that finds, or indicates the lack of, a correct answer to a question in a context paragraph. Our goal is to learn an ensemble of heterogeneous SQuAD2.0 models that, when blended properly, outperforms the best model in the ensemble per se. We created a stacking ensemble that combines top-N predictions from two models, based on ALBERT and RoBERTa, into a multiclass classification task to pick the best answer out of their predictions. We explored various ensemble configurations, input representations, and model architectures. For evaluation, we examined test-set EM and F1 scores; our best-performing ensemble incorporated a CNN-based meta-model and scored 87.117 and 90.306, respectively -- a relative improvement of 0.55% for EM and 0.61% for F1 scores, compared to the baseline performance of the best model in the ensemble, an ALBERT-based model, at 86.644 for EM and 89.760 for F1.
Learning Joint Acoustic-Phonetic Word Embeddings
Aug 01, 2019

Most speech recognition tasks pertain to mapping words across two modalities: acoustic and orthographic. In this work, we suggest learning encoders that map variable-length, acoustic or phonetic, sequences that represent words into fixed-dimensional vectors in a shared latent space; such that the distance between two word vectors represents how closely the two words sound. Instead of directly learning the distances between word vectors, we employ weak supervision and model a binary classification task to predict whether two inputs, one of each modality, represent the same word given a distance threshold. We explore various deep-learning models, bimodal contrastive losses, and techniques for mining hard negative examples such as the semi-supervised technique of self-labeling. Our best model achieves an $F_1$ score of 0.95 for the binary classification task.