 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGestalt: a Stacking Ensemble for SQuAD2.0
Paper and Code

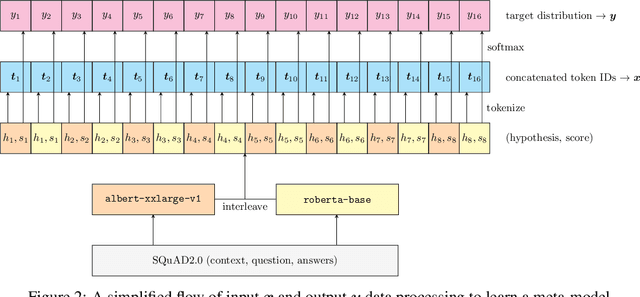

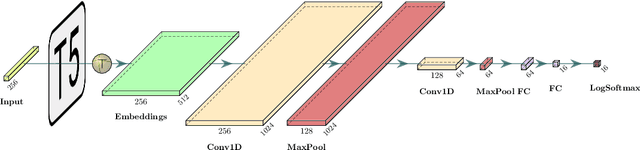
We propose a deep-learning system -- for the SQuAD2.0 task -- that finds, or indicates the lack of, a correct answer to a question in a context paragraph. Our goal is to learn an ensemble of heterogeneous SQuAD2.0 models that, when blended properly, outperforms the best model in the ensemble per se. We created a stacking ensemble that combines top-N predictions from two models, based on ALBERT and RoBERTa, into a multiclass classification task to pick the best answer out of their predictions. We explored various ensemble configurations, input representations, and model architectures. For evaluation, we examined test-set EM and F1 scores; our best-performing ensemble incorporated a CNN-based meta-model and scored 87.117 and 90.306, respectively -- a relative improvement of 0.55% for EM and 0.61% for F1 scores, compared to the baseline performance of the best model in the ensemble, an ALBERT-based model, at 86.644 for EM and 89.760 for F1.